
The 2026 AI Engineering Report
In collaboration with Notion and Vercel, we surveyed more than 1,000 engineers building in AI about everything from which models they’re using, to how they approach cost, to whether their non-technical teammates are shipping features. And, of course, if they think we’ll get GPUs in space.
Some highlights:
- The year of image generation: GenAI for images grew faster than all other modalities and finally hitting its stride…but audio is still the sleeper pick
- Open weights models are popular, but not self sufficient: more than half of respondents are using open weight models, but almost all alongside closed source ones
- A wave of standardization may be forming: >50% of respondents say there is at least some standardization occurring on fewer AI tools at their org
- Cost has gone from footnote to primary driver: ¾ of respondents are adjusting their AI usage based on cost, and 40% say cost regularly shapes how ambitiously they use AI
- It’s an agent free-for-all, but can it last? Among teams using agents, the share with write permissions increased from 52% to 89% — a 1.7x increase. And because far more teams are using agents overall, the share of all respondents using write-enabled agents is up more than 3x. Yet, there’s no consensus on how to properly monitor and set up guardrails for them.
And there’s a lot more. So without further ado, let’s dive in.
Demographics / who we surveyed
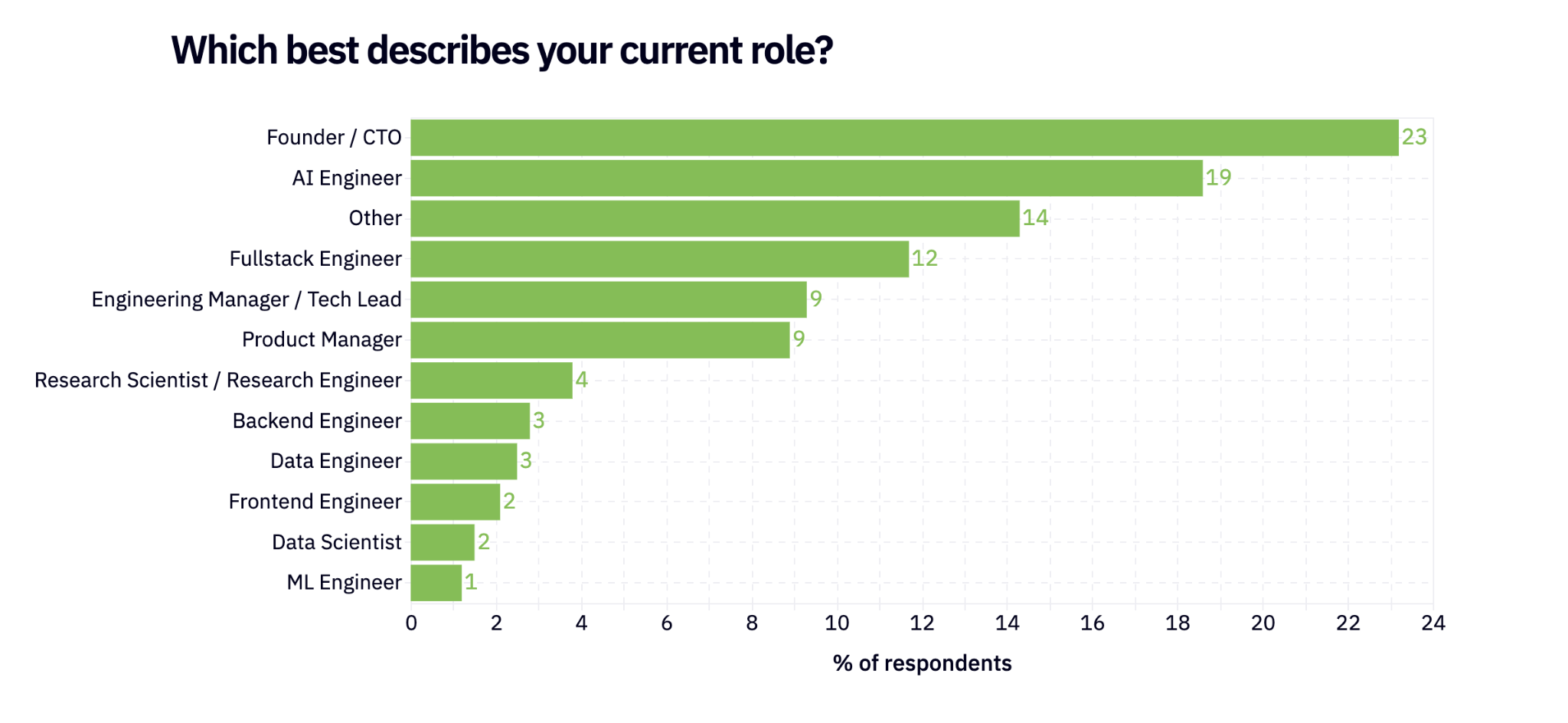
Who exactly is working on the engineering side of AI? The largest group of respondents described themselves as founders or AI Engineers (swyx o’ clock).
For the 3rd year in a row, many of the most seasoned developers out there are relative newcomers to AI: of respondents with 10+ years of software experience, 51% have 3 years or fewer of AI experience.
At the same time, the leading edge is starting to even out: the share of respondents with less than 1 year of AI experience dropped from 1 in 10 last year to roughly 1 in 34 this year.
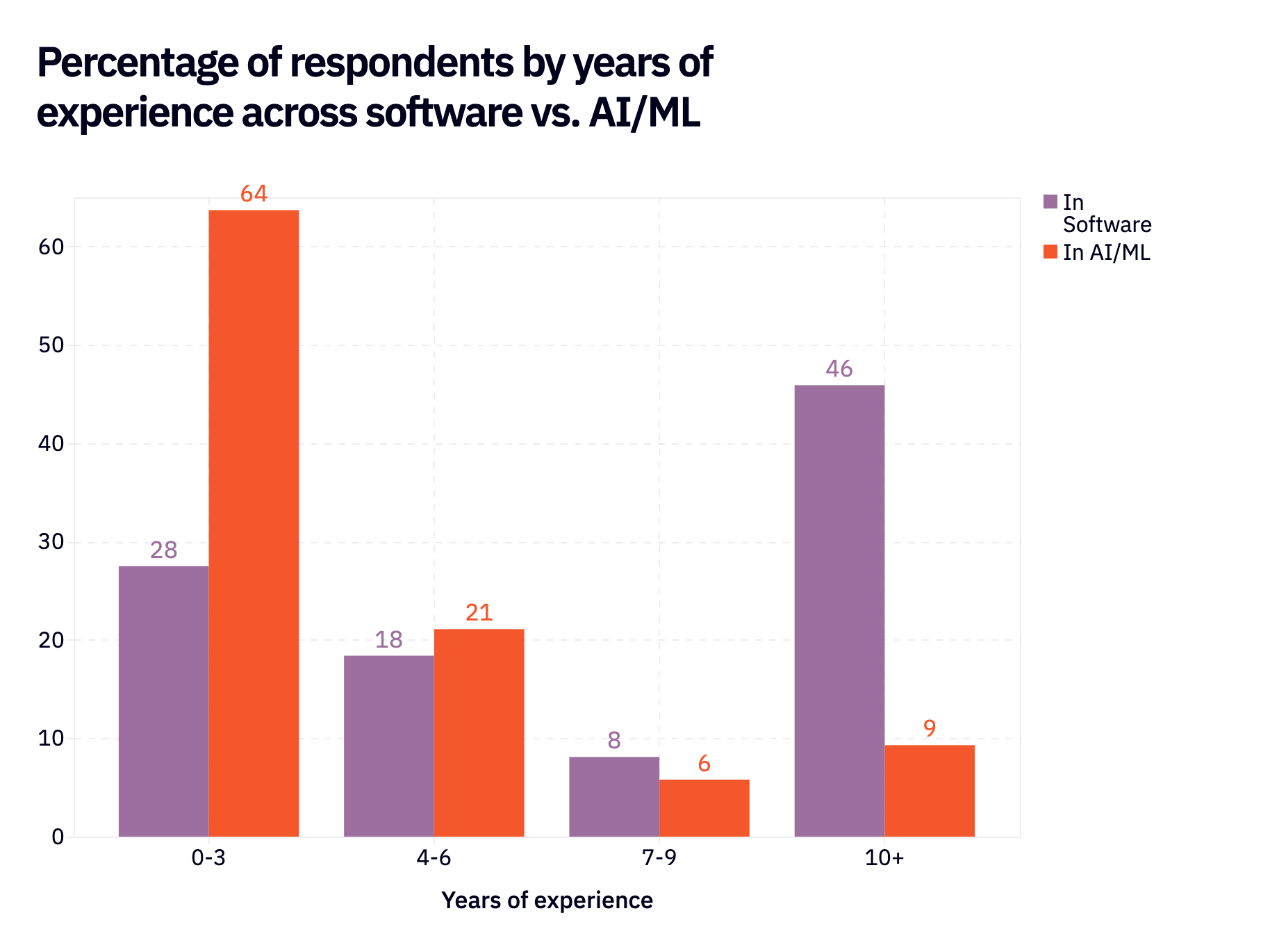
You can reframe the above chart as “how many years of AI/ML experience do each of these buckets have?” which we’ve graphed below. Even very senior engineers with 10+ years of experience only have, on the median, 3 years of experience in AI/ML.
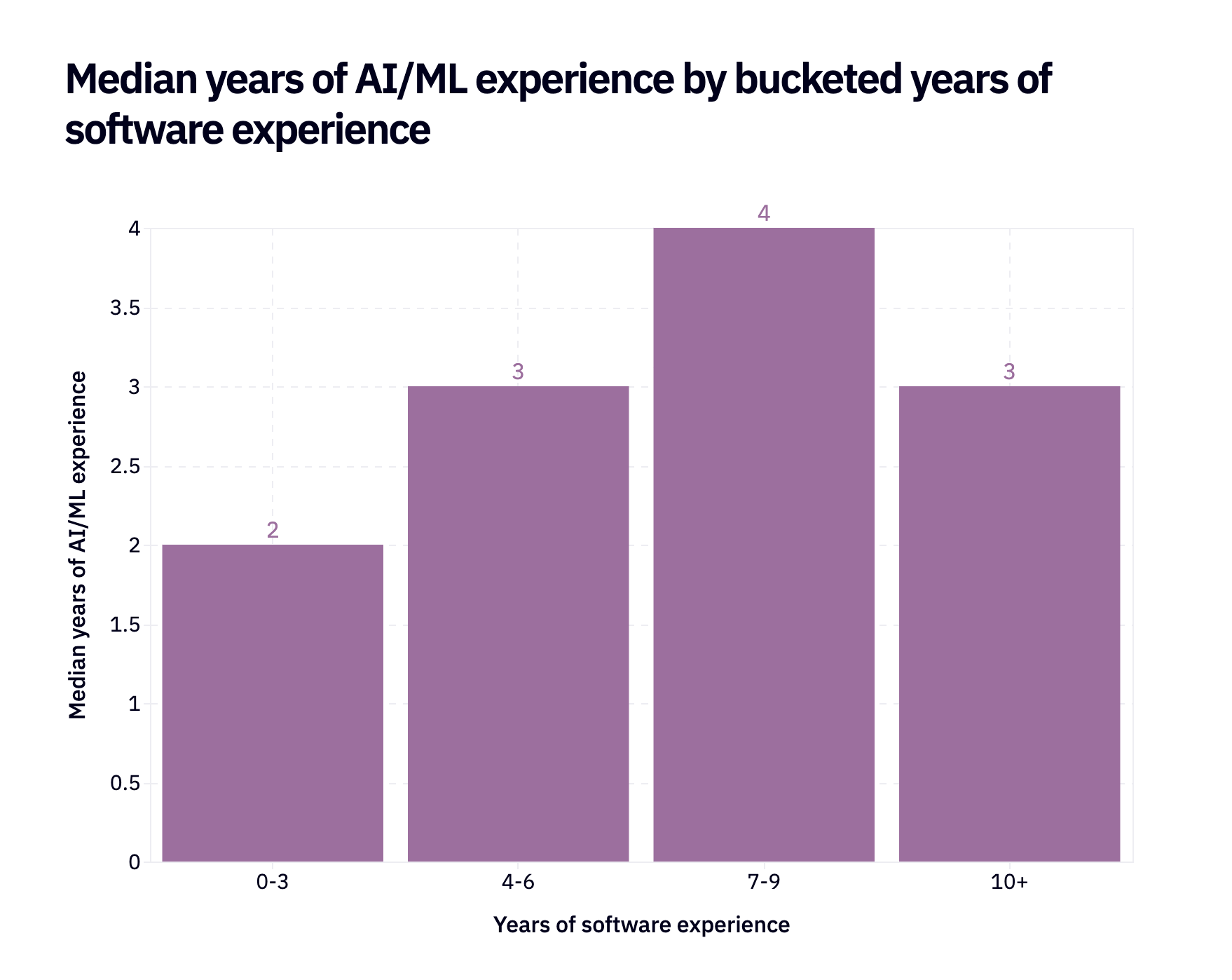
But if you look at the 0-3 bucket, you’ll see that more junior software engineers, as a percentage of their overall software experience, are more AI-native. If you’re getting into the workforce now, software engineering experience is AI/ML experience.
AI at work (or, a primer on model usage)
This section covers the types of models that respondents use and how they use them.
Differences in usage and satisfaction across modalities
Across the board, we’re seeing meaningful increases in usage in all modalities (especially outside of text, which basically everyone is using). Note that survey respondents are, by all accounts, a fairly AI-native group of people…and the majority of them still aren’t using most modalities. There’s such incredible growth yet to come.
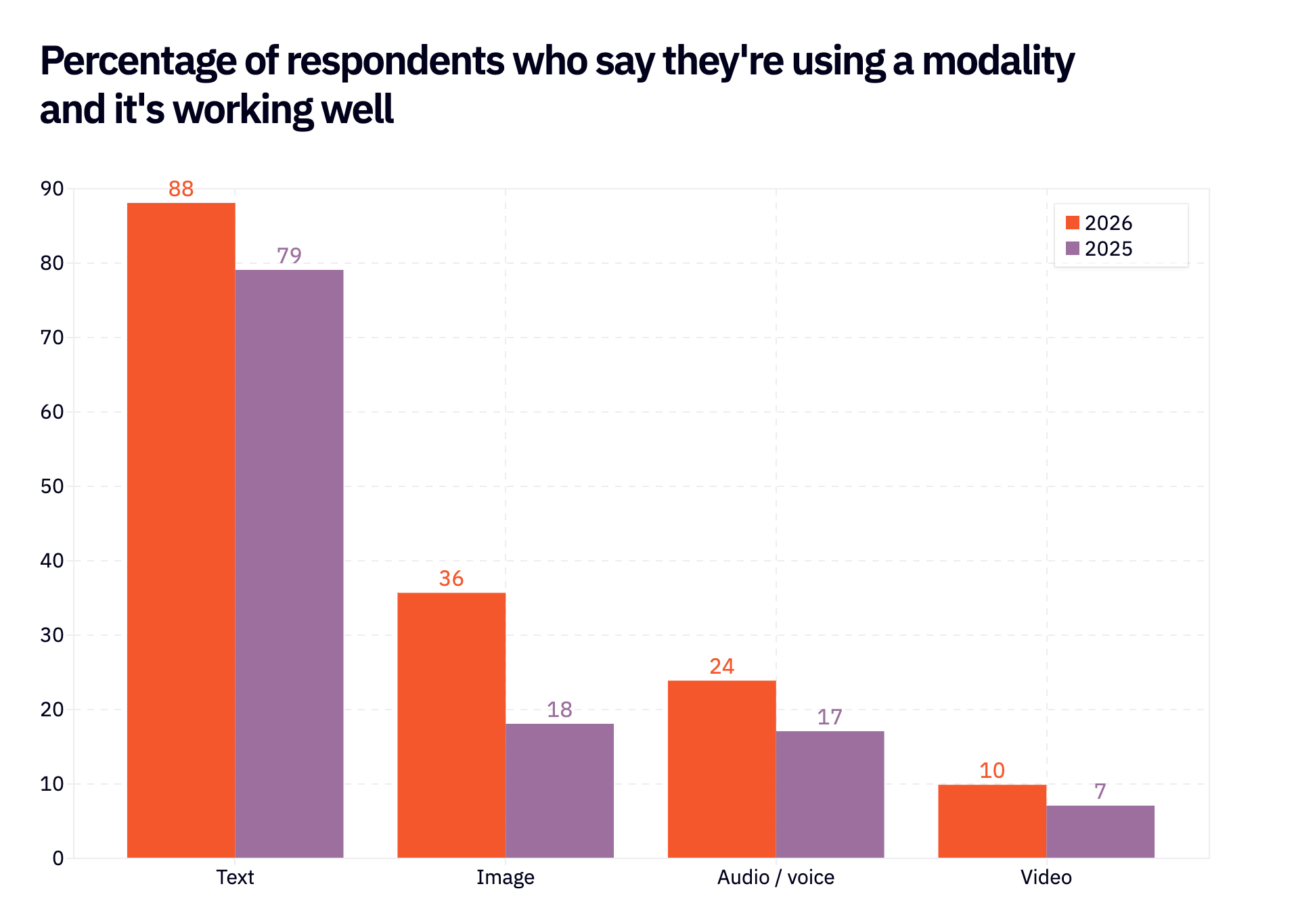
The biggest jump from last year came from image generation. 2x as many respondents (36% vs. 18% in 2025) say they’re using generative AI for images and it’s working well. Many of the best image gen solutions saw V2s over the past 6-9 months (e.g. NanoBanana 2, ChatGPT Images 2.0) and it seems to be paying off.
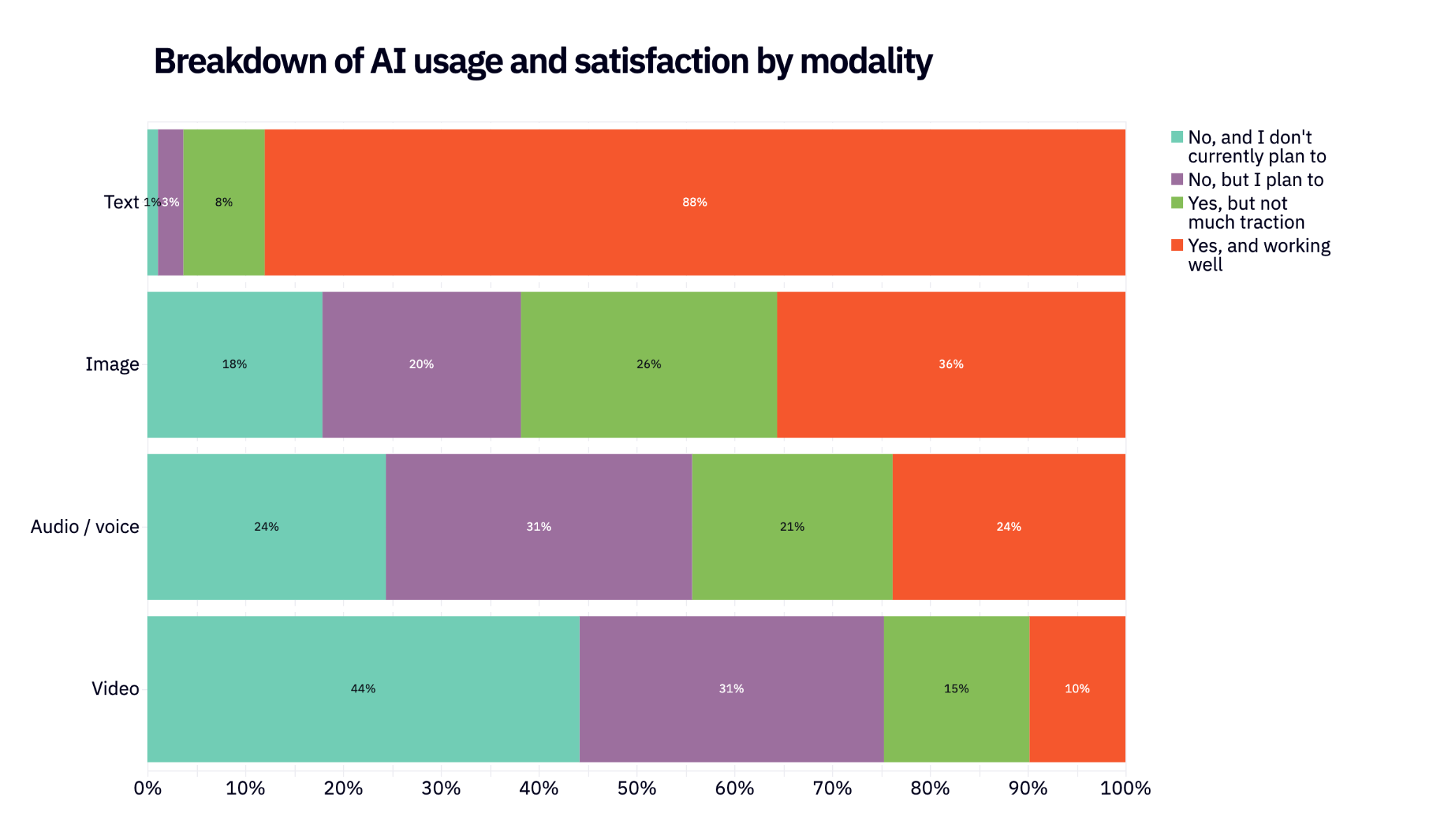
One thing we’re all wondering: what’s going on with audio? Last year, we argued that audio was poised for a huge adoption swing; 37% of respondents who weren’t using audio said they planned to soon. There has definitely been growth since then – 24% of respondents are happily using audio vs. 17% last year – but it’s not the kind of growth you might have expected. Not only that, but the intent-to-adopt rate for audio is even higher than last year: 56% of those not using audio plan to use it soon.
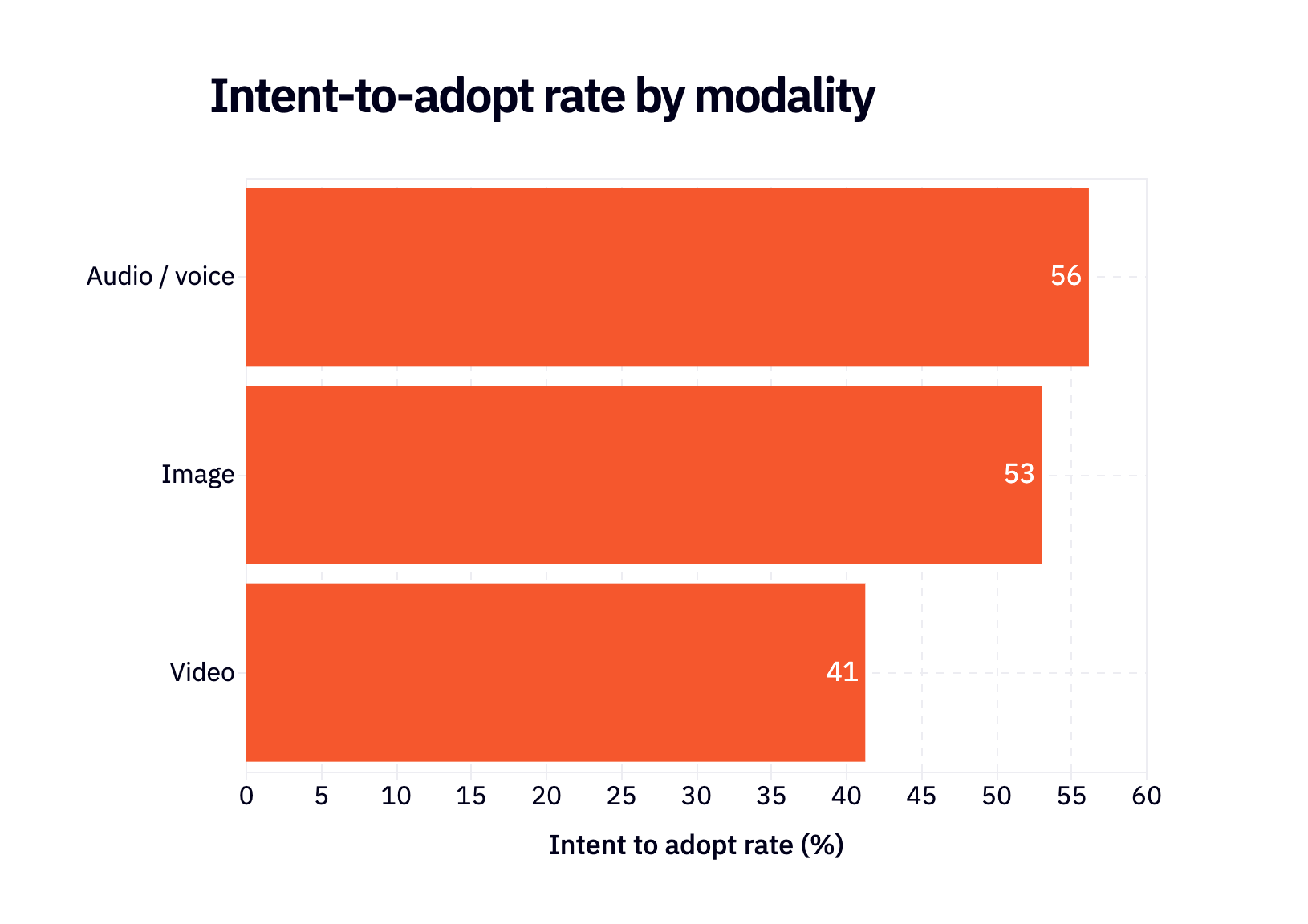
What’s holding people back from building with audio?
The models people are choosing and why
There has been a lot written over the past few months about open weights models. The data in the survey shows that they’re getting infinitely popular…but almost nobody is using them independently. Today open source is best thought of as a helpful companion to closed source but not yet a direct replacement.
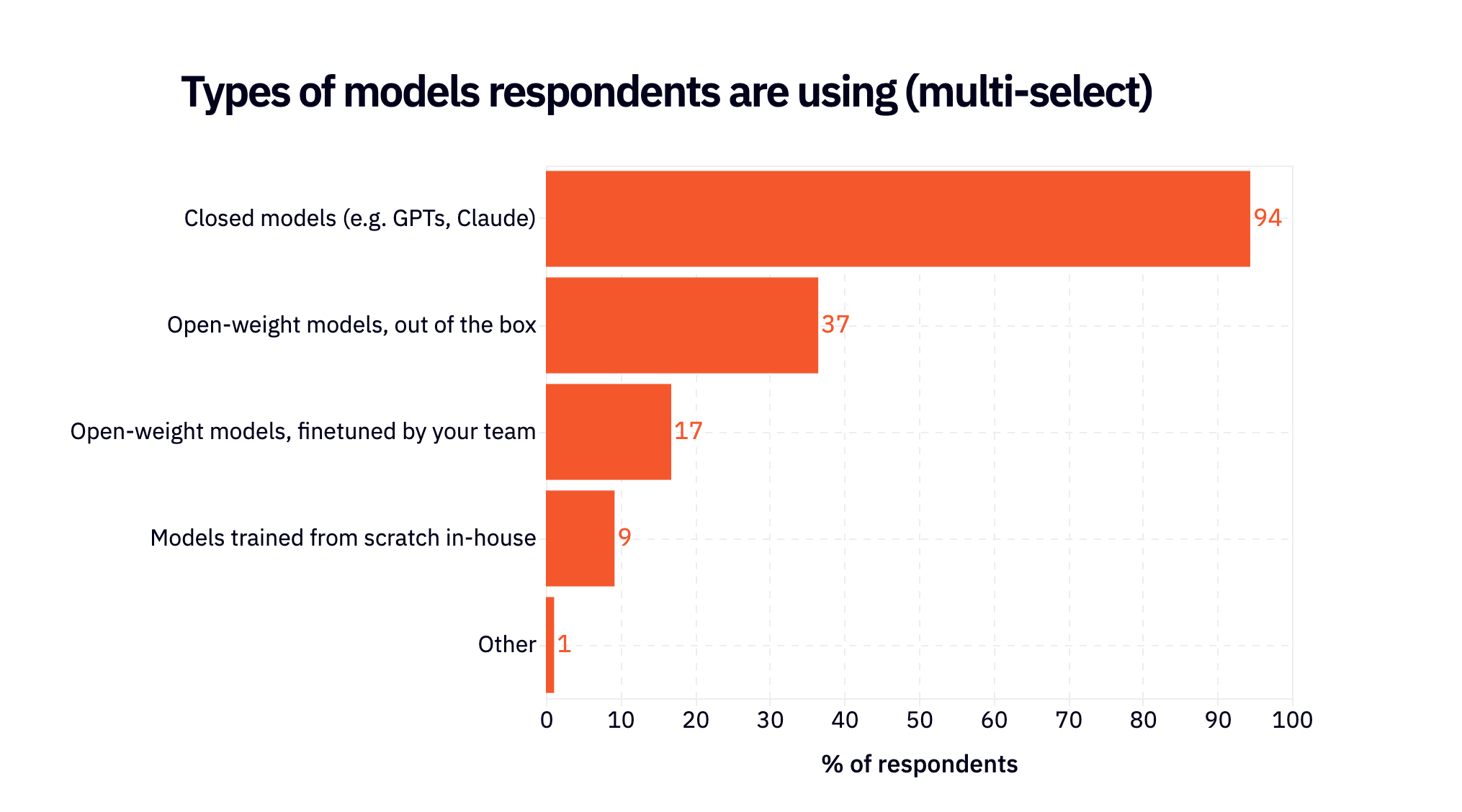
Of the 45% of respondents using open-weight models (either out of the box or finetuned), >90% are also using closed models.
Open vs. closed is actually only a primary consideration for 5% of respondents. The most important quality by far is…quality, followed by agentic capabilities and then cost (we’ll come back to this).
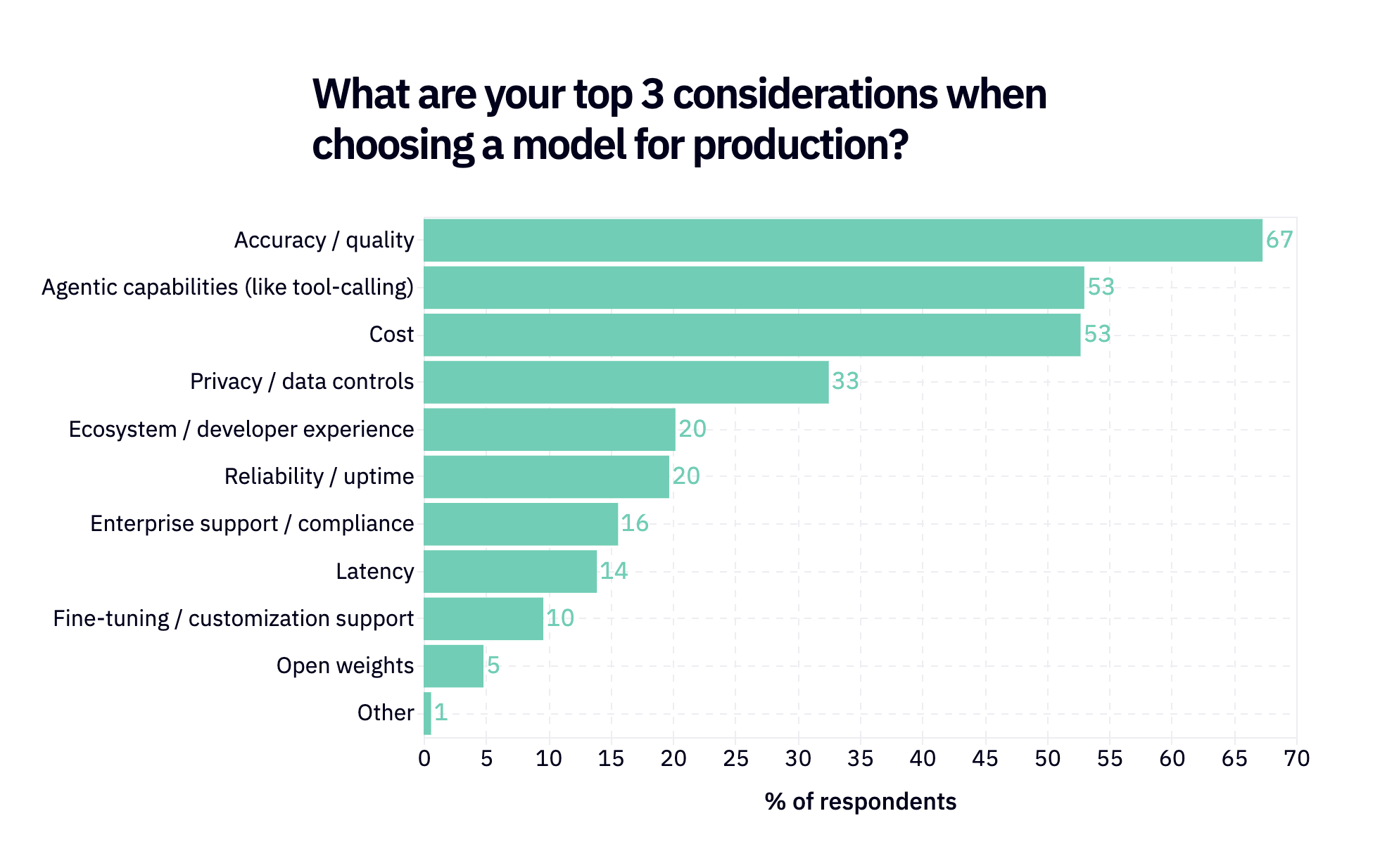
Only 20% of respondents put reliability / uptime in their top 3 considerations. This is an interesting data point when contrasted with the public X uproar every time Claude Code has an outage. It’s annoying when models aren’t working, and sometimes you just want to complain about it – but as long as they work most of the time, people don’t seem to really care.
The overwhelming majority (87%) of respondents are actively using multiple models together. The top three ways they route are: 44% by task type, 26% run multiple and compare outputs, and 11% route based on cost.
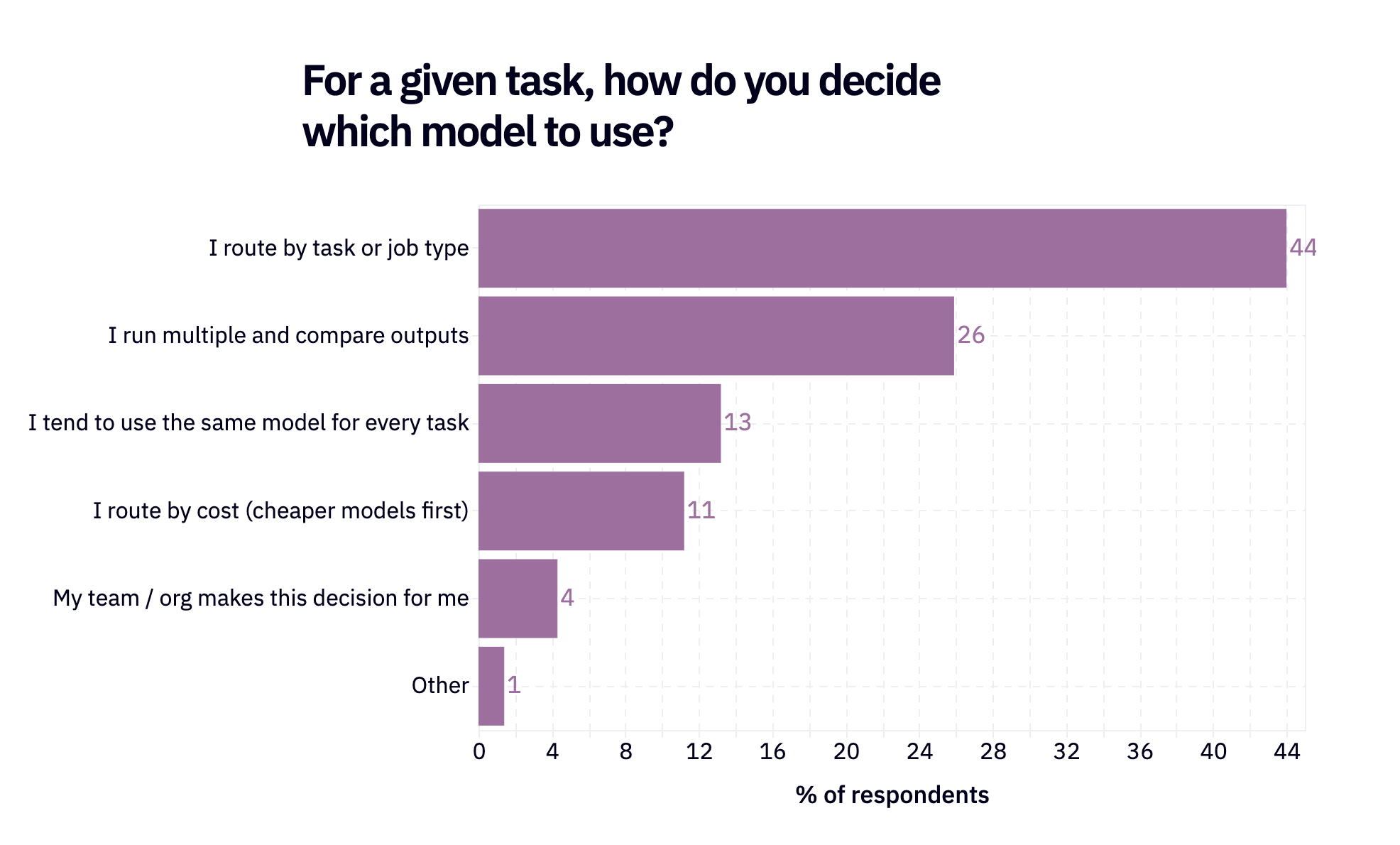
But this polycule might not last. The data imply that The Great Standardization may be coming: >50% of respondents say there is at least some standardization occurring on fewer AI tools within their org.
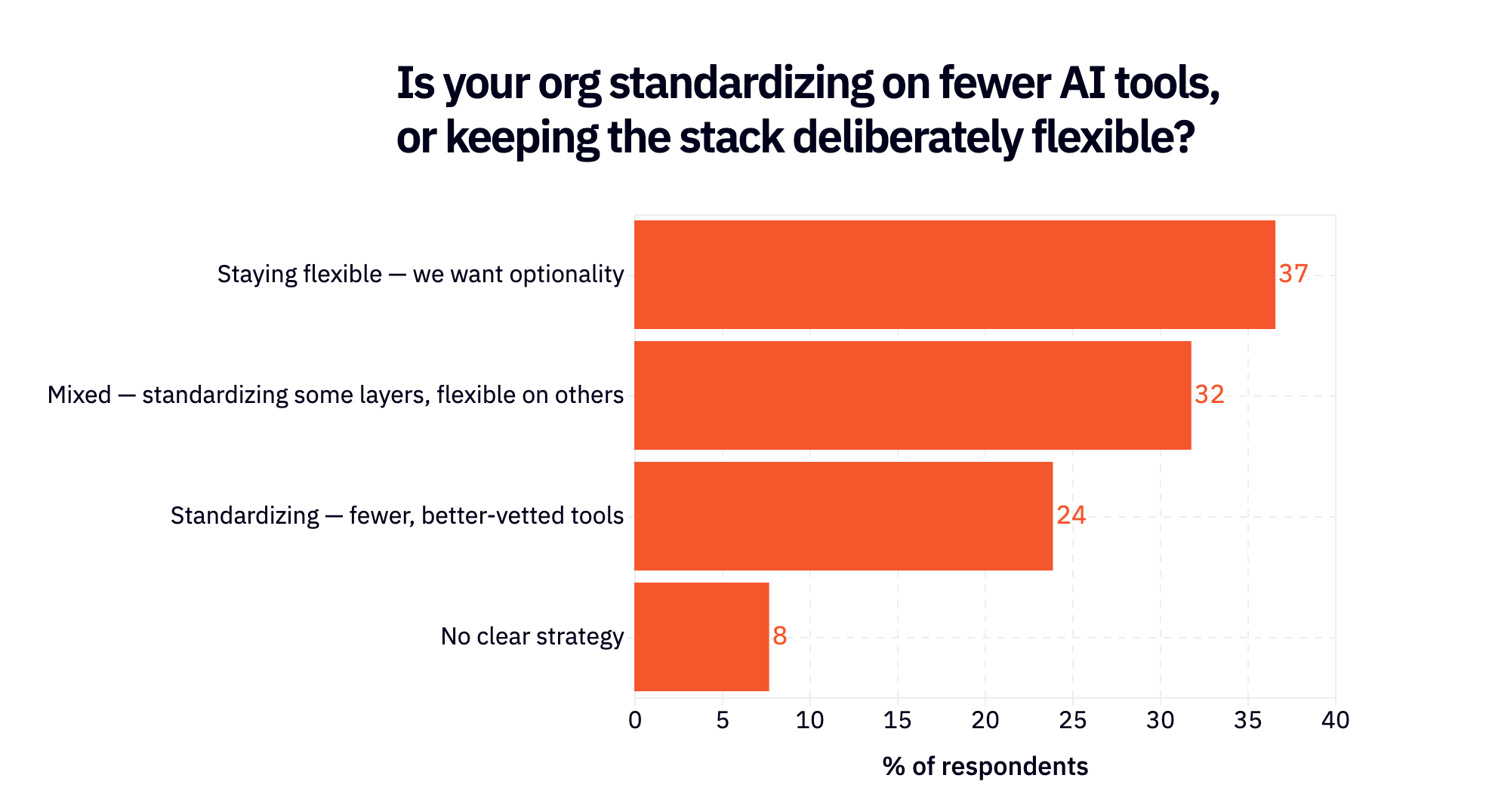
Cost is becoming a first-class consideration
Thematically, 2025 was all vibes and pure usage while 2026 is shaping up to be the year where we started thinking about value. As model improvements flatten out and prices continue to go up, we are starting to see cost play a major role in how organizations make AI decisions.
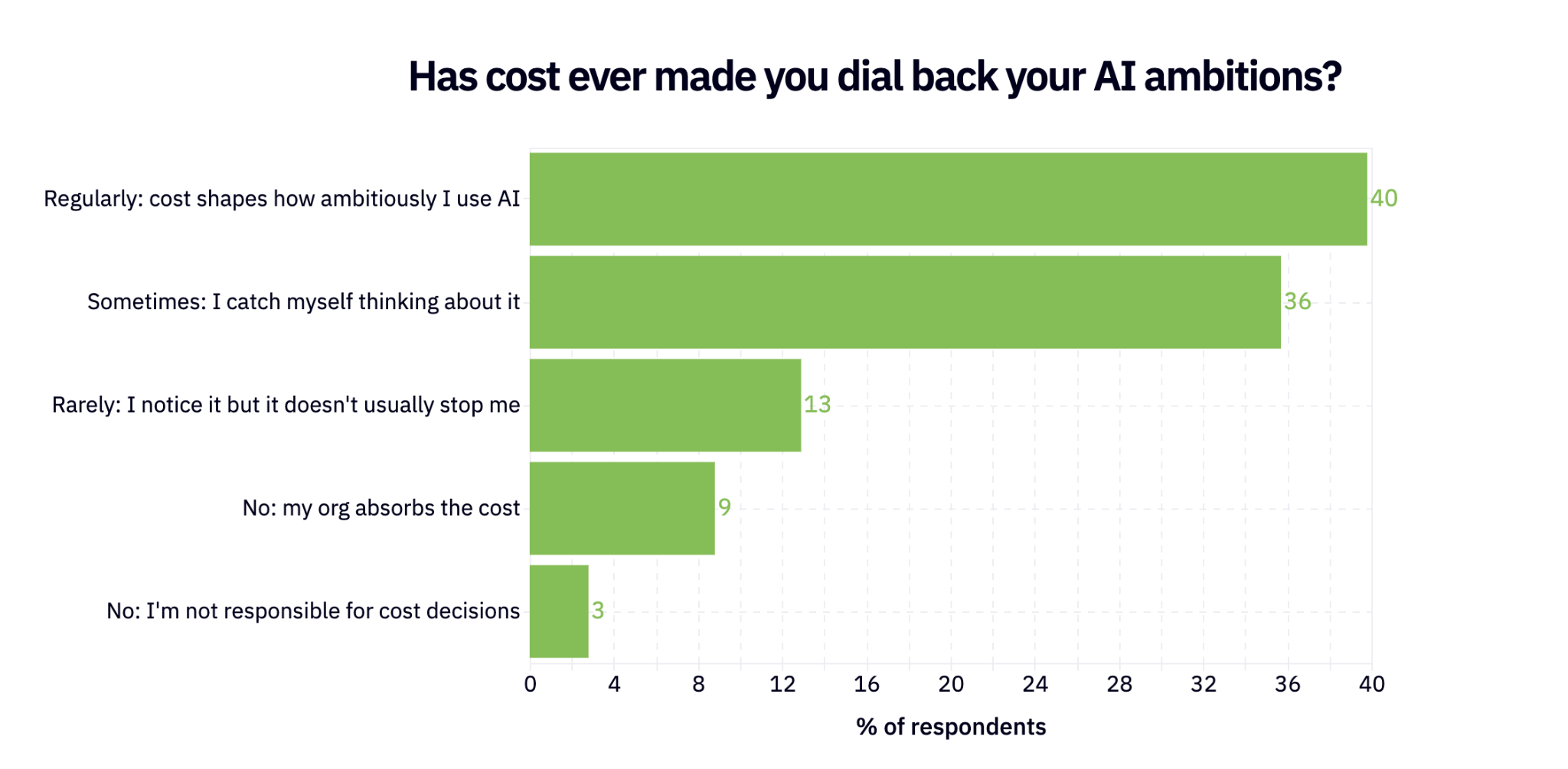
40% of respondents say cost regularly shapes how ambitiously they use AI, and 36% say it sometimes does. All in all ¾ of respondents are adjusting their AI usage based on cost.
This sounds…obvious, but if you can put yourself in your own shoes just 12 months ago, it was anything but.
The year of agents writing data and semi-autonomy (+monitoring)
Agents were a meme in 2025 and are now just how AI is used in 2026. Agent usage nearly doubled relative to last year. Among teams using agents, 89% say those agents can write data, compared with 52% last year. But the majority still require a human in the loop.
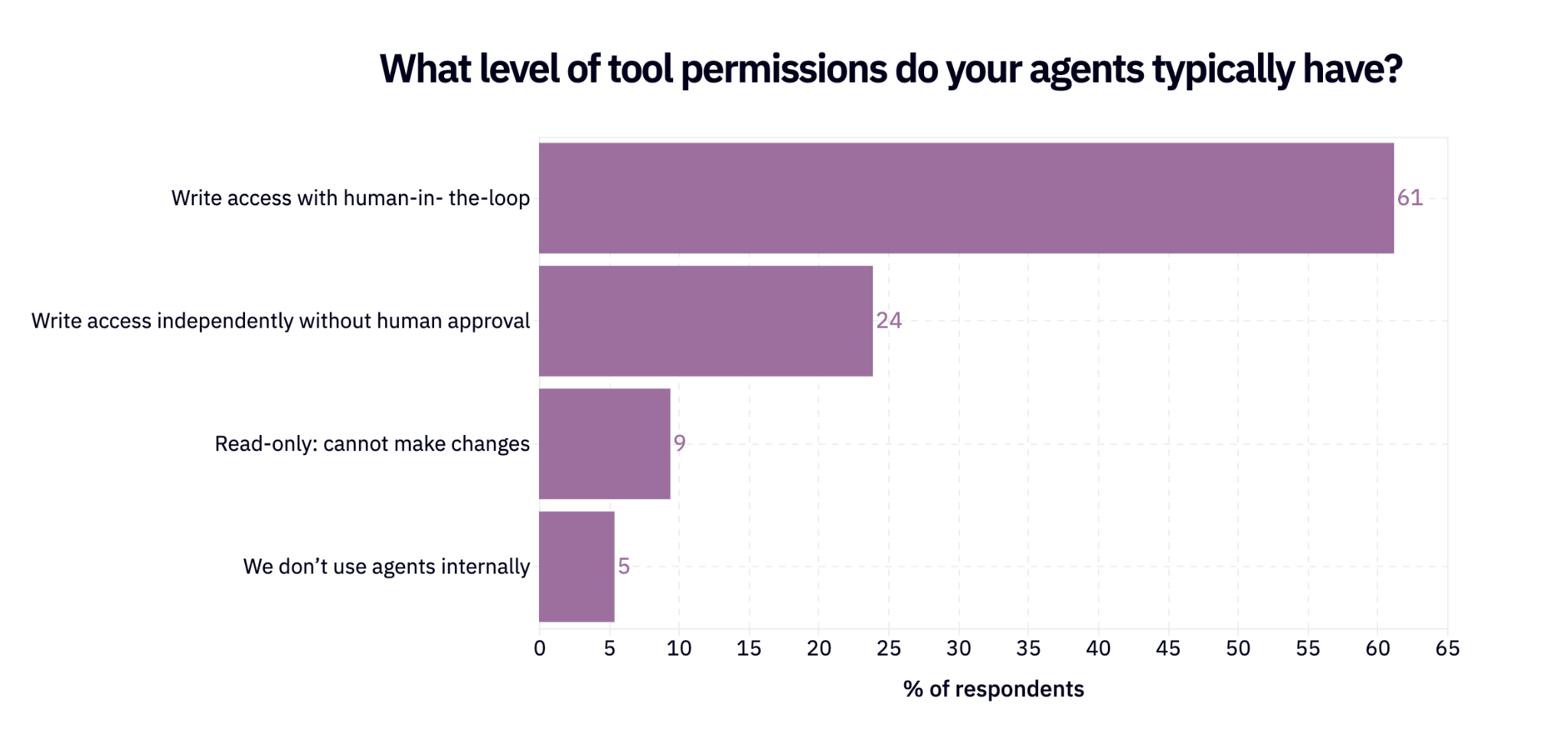
Part of the reason agents can’t fully roam free yet is that nobody is quite sure how to control or manage them. What I would call fairly primitive guardrails are the top 2 options in the survey – human in the loop approvals, and simply gating agents from permissions – while results are scattered for other strategies. People are basically trying everything.
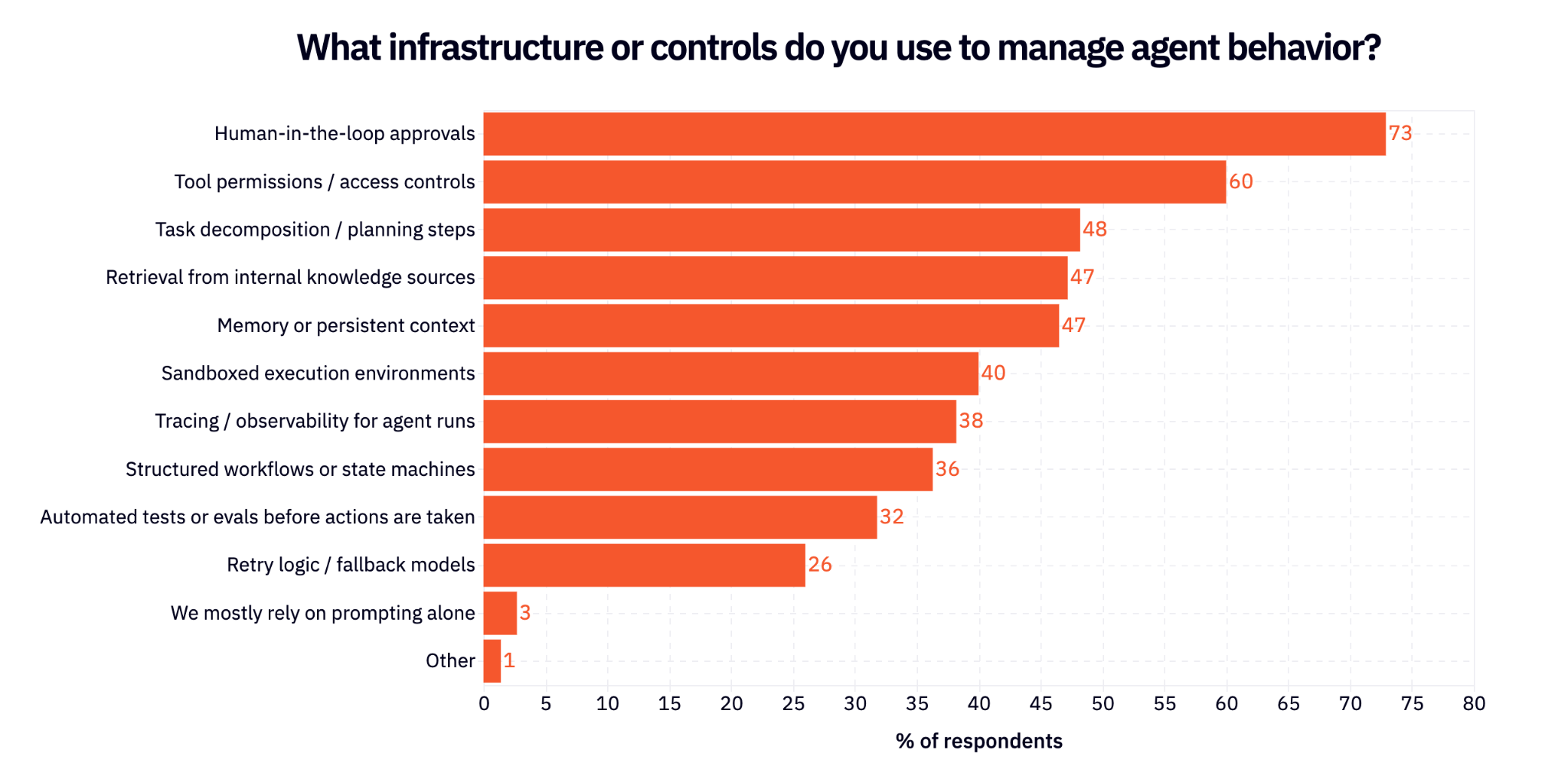
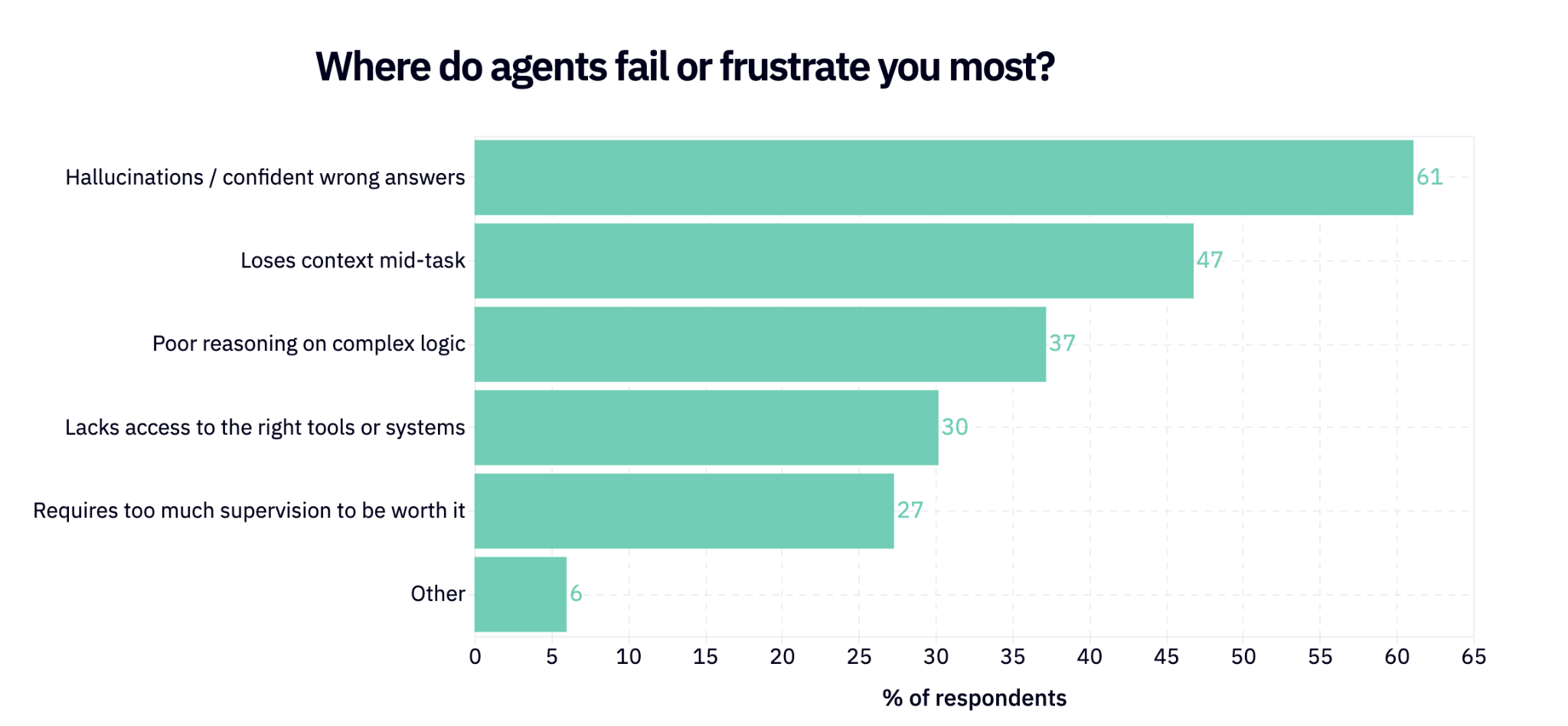
The area where agents mess up the most is in the quality of their responses: 61% say that where agents fail or frustrate them the most is hallucinations.
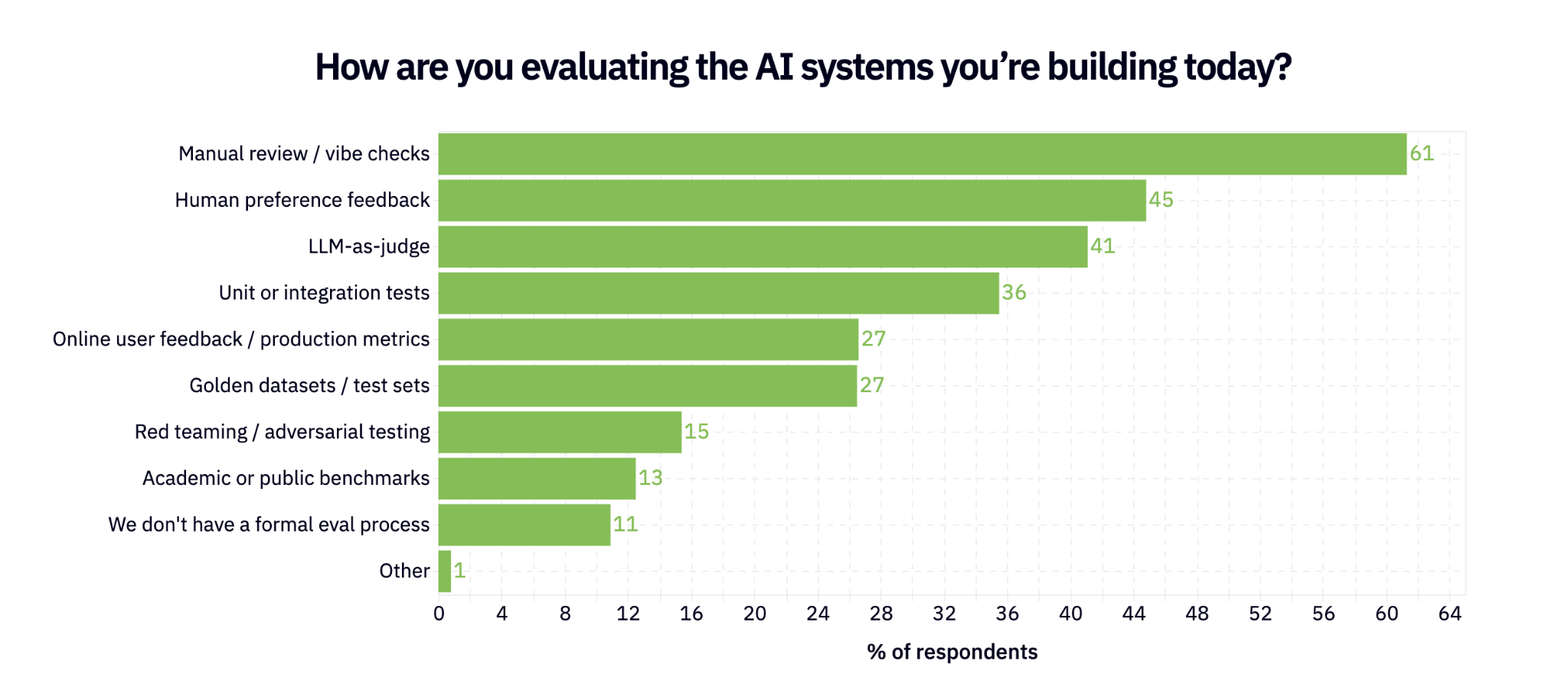
Evals, monitoring, and adapting model behavior
The cost narrative continues: cost is one of the most highly monitored items in production (after quality / task success, duh). Almost half of respondents are actively monitoring cost in prod.
When it comes to actually adapting model behavior based on these supposed evals everyone is talking about, the majority of respondents are still (just) updating their prompts. This is starting to feel a bit primitive and nobody really talks about prompt engineering anymore. But here it is.
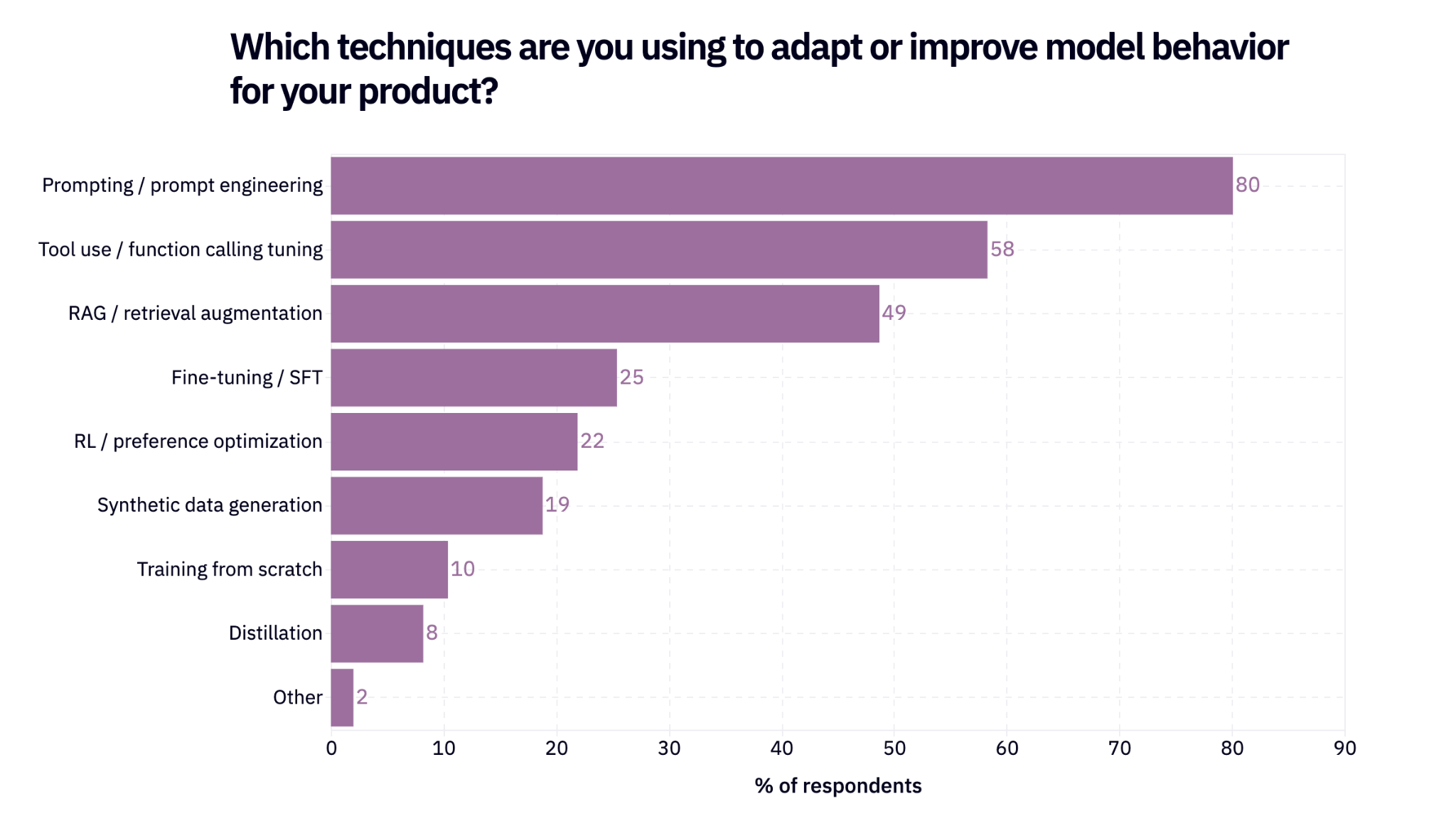
Another potential narrative violation: almost 50% of respondents say they’re using RAG of some sort.
The AI engineering stack + build vs. buy
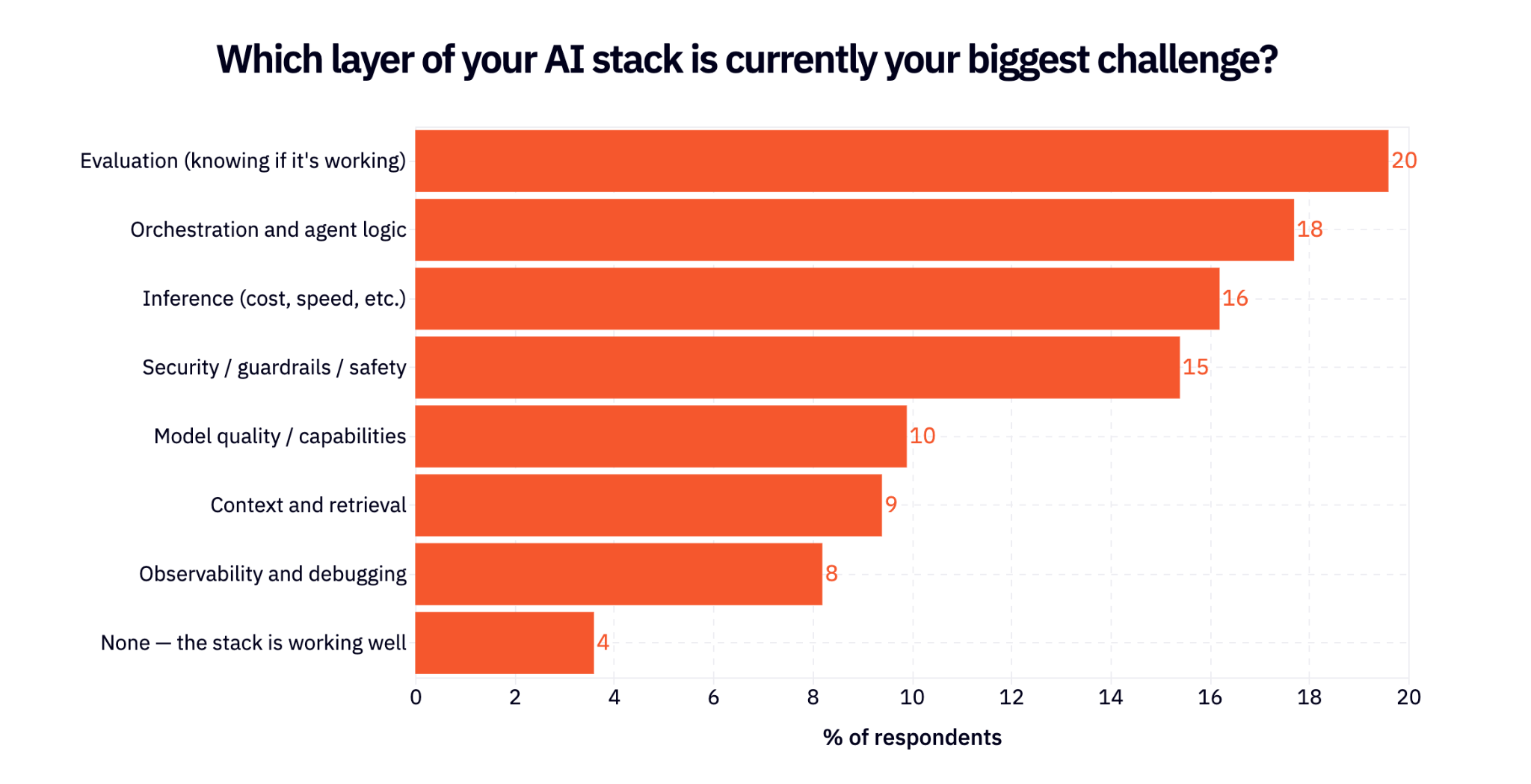
If we zoom out to look at the AI engineering stack as a whole, there’s no widespread agreement on what the biggest challenge is. Evals, orchestration and agent logic, inference, and security are all within a few points of each other on the survey. In other words, we have a long way to go (a solid 4% think the stack is working well 😂).
We asked respondents about how they’re approaching build vs. buy for different layers of the stack. They were able to mark whether they’ve built or bought for particular layers, plus whether they’re happy with that decision or are considering switching (e.g. have built finetuning, but are considering buying instead).
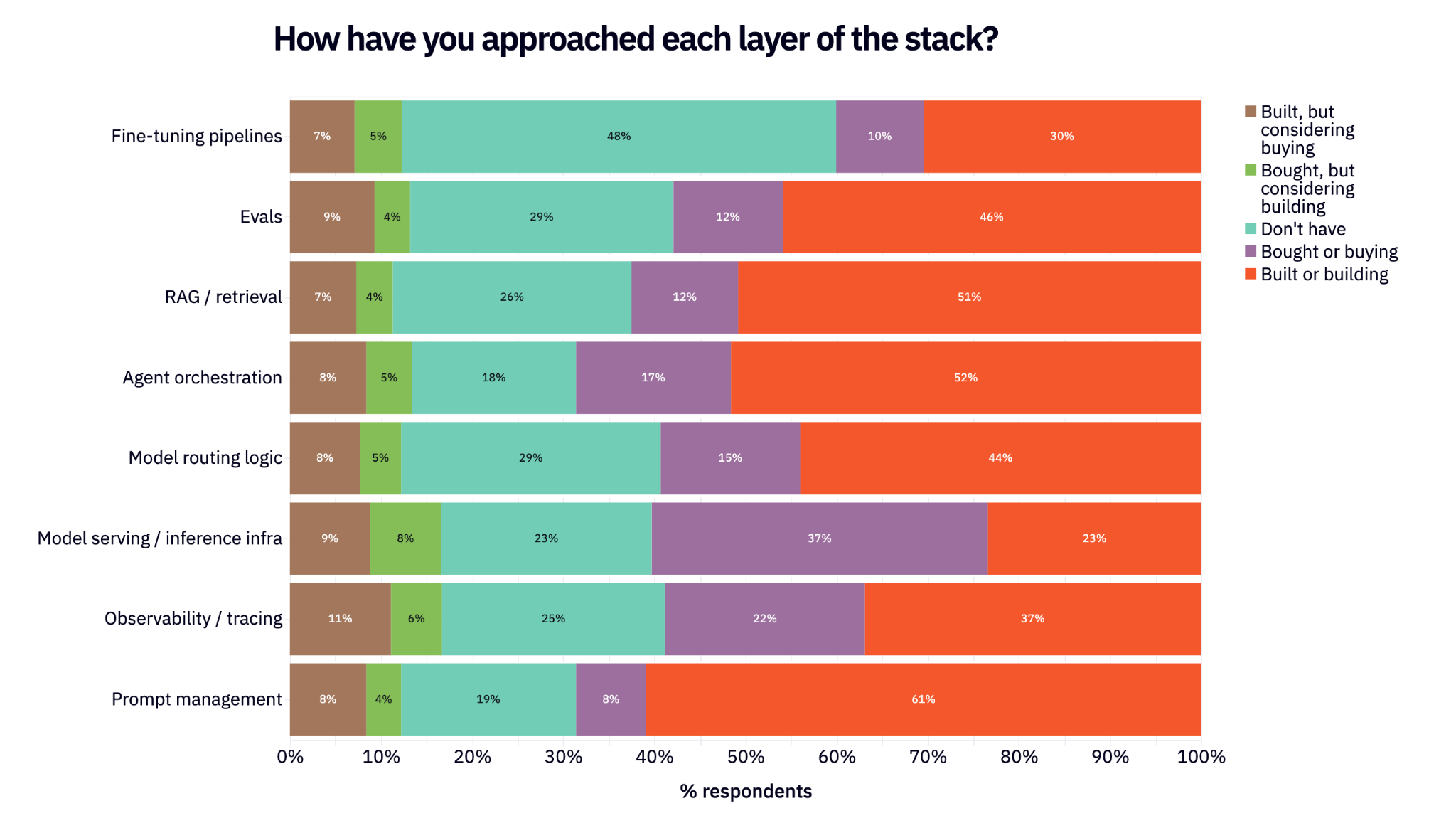
One of the most interesting takeaways is that inference / model serving is far and away the most commonly bought layer of the stack: 45% have bought (highest in the survey, 37% happy with that decision) and only 23% have built (lowest in the survey).
Prompt management is the opposite. Out of all layers of the stack, it’s the most commonly built and least commonly bought.
On the reverse side, we asked respondents where AI has been the most impactful on their development stack (they could choose their top 3). A surprising takeaway is that AI has impacted all parts of the SWE stack, not just codegen: almost half (48%) say planning and spec writing, and even 28% say backend / API.
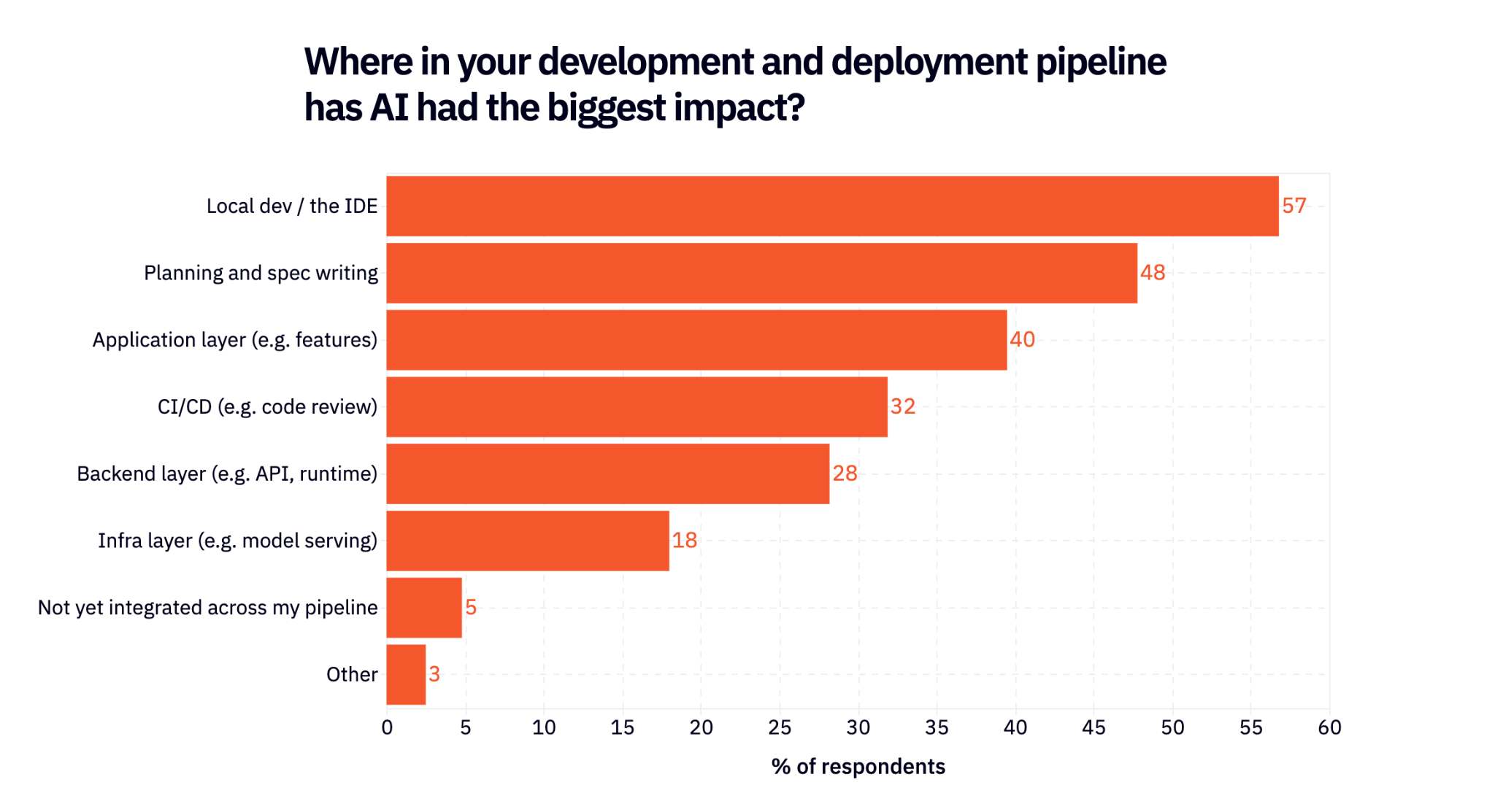
Shifting roles and organizational impact
We are clearly seeing AI move from experimental / tinkering technology to broadly impactful on the organization. The good news is that basically every respondent (97%) is feeling a positive downstream effect of AI in the org – largely around experimentation and faster shipping. The AI h8ers will be silenced!
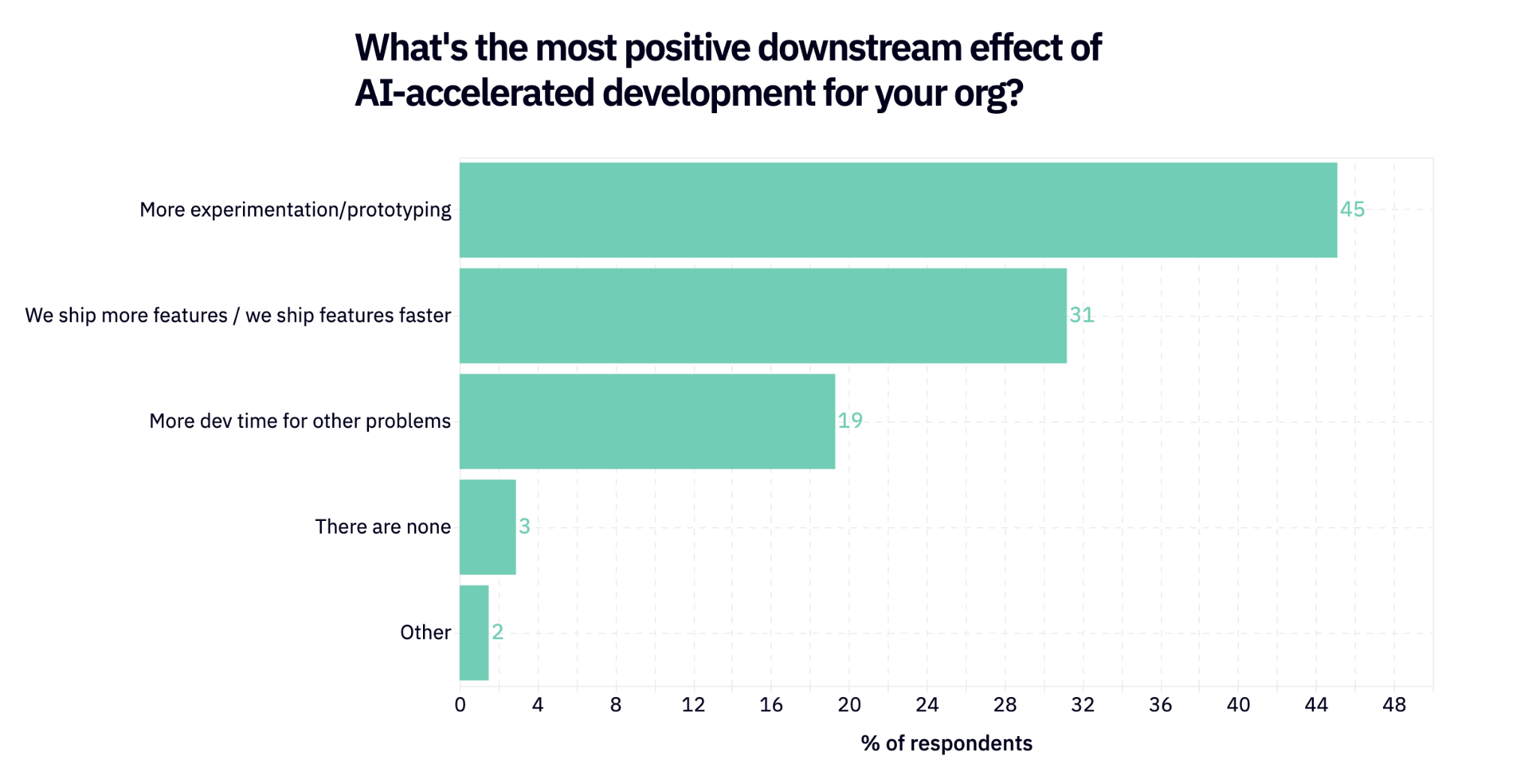
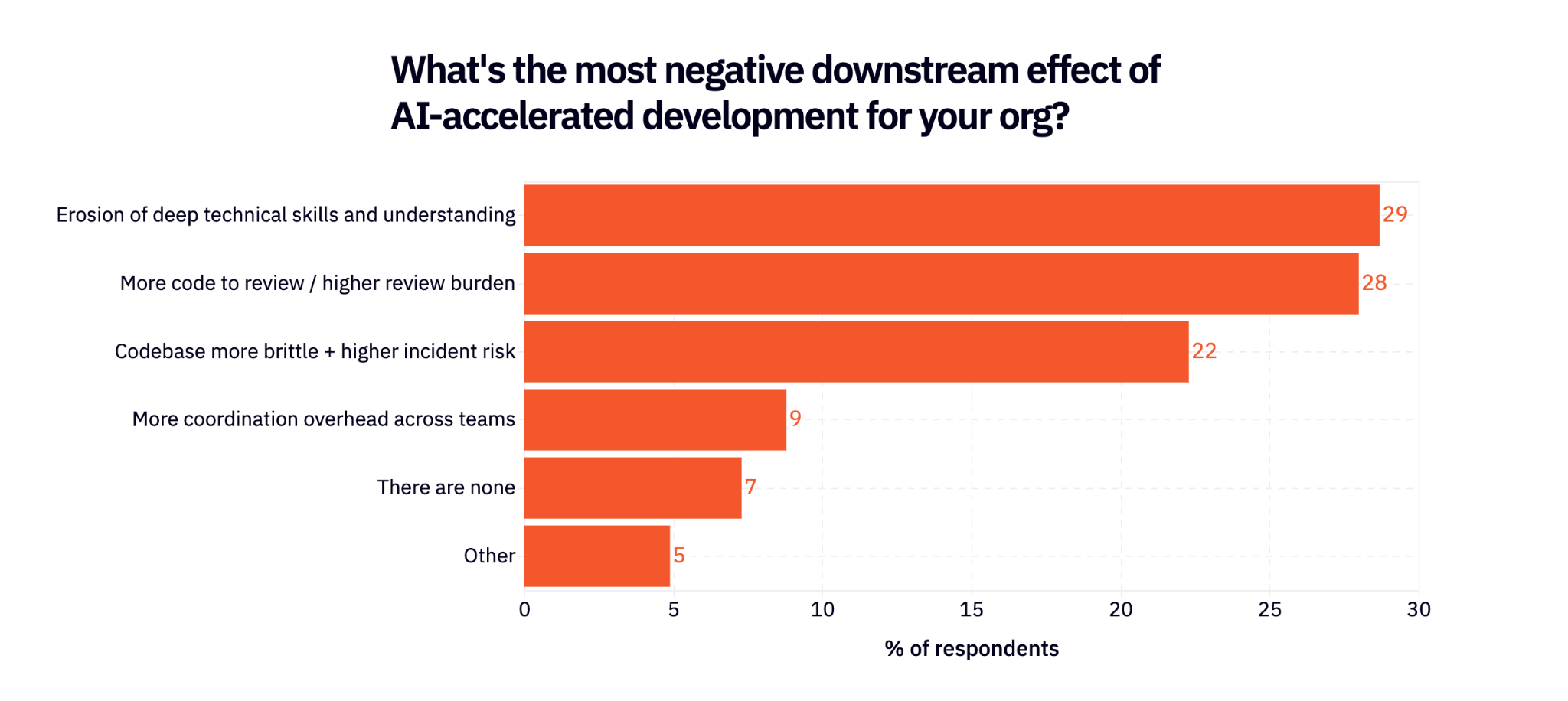
But there is a cost to every dalliance. 93% of respondents are also feeling negative downstream effects, the most common being a widely discussed erosion of deep technical skills and understanding. All of the consequences of infinitely cheap code generation show up here.
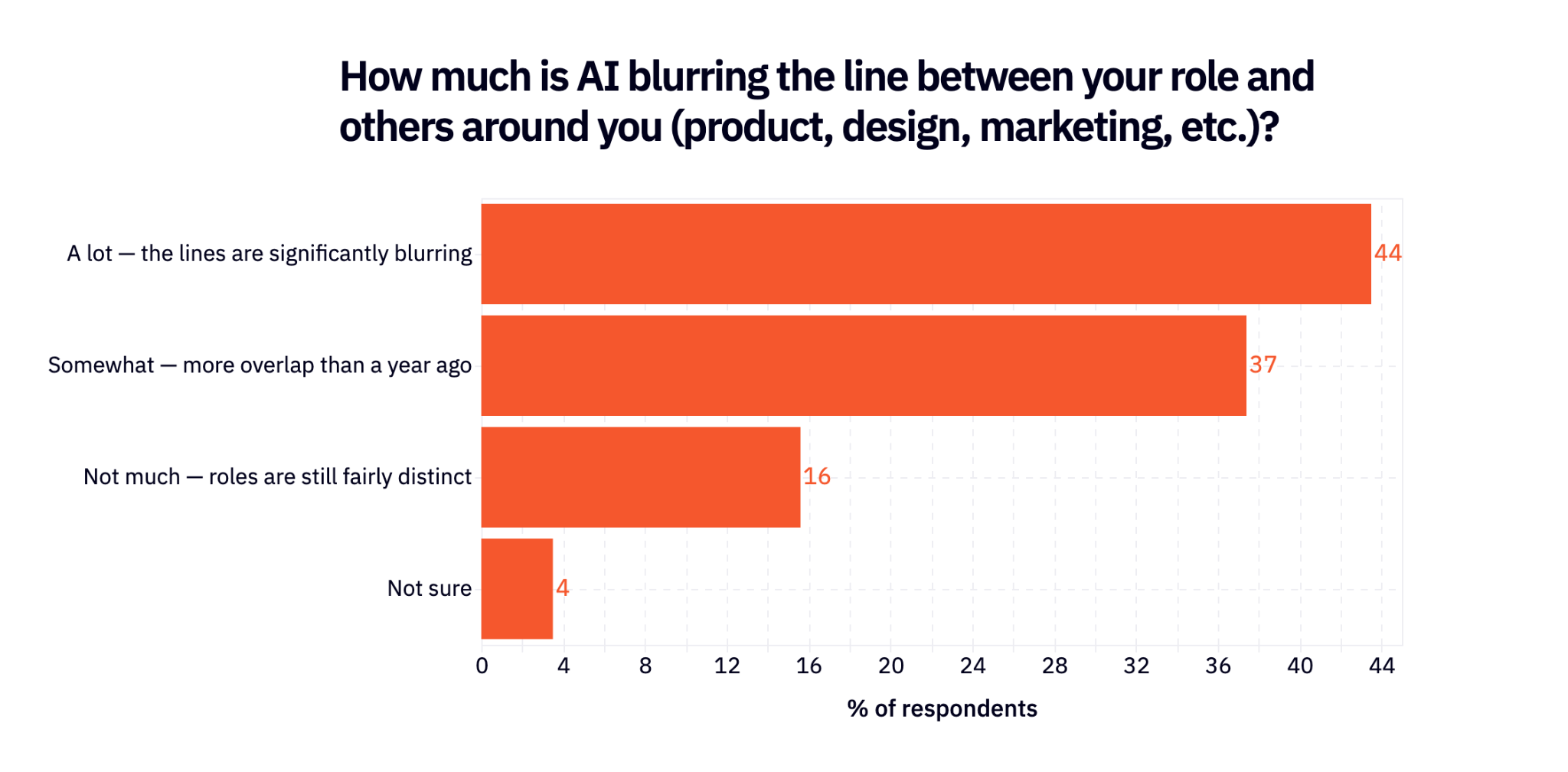
Because of all of this, traditional roles in the product organization are already blurring. 44% of respondents say this is happening in a significant way and another 37% say it’s happening somewhat.
This is perhaps most acutely felt as it relates to shipping software, once a domain exclusively of the engineer. <50% of respondents say that non-developers are shipping at least features, mostly internal. But 17% say that they are regularly shipping full size customer-facing ones, which blows my mind. And of that majority that aren’t shipping features, many (32%) are at least building helpful things internally.
Rapid fire and predictions
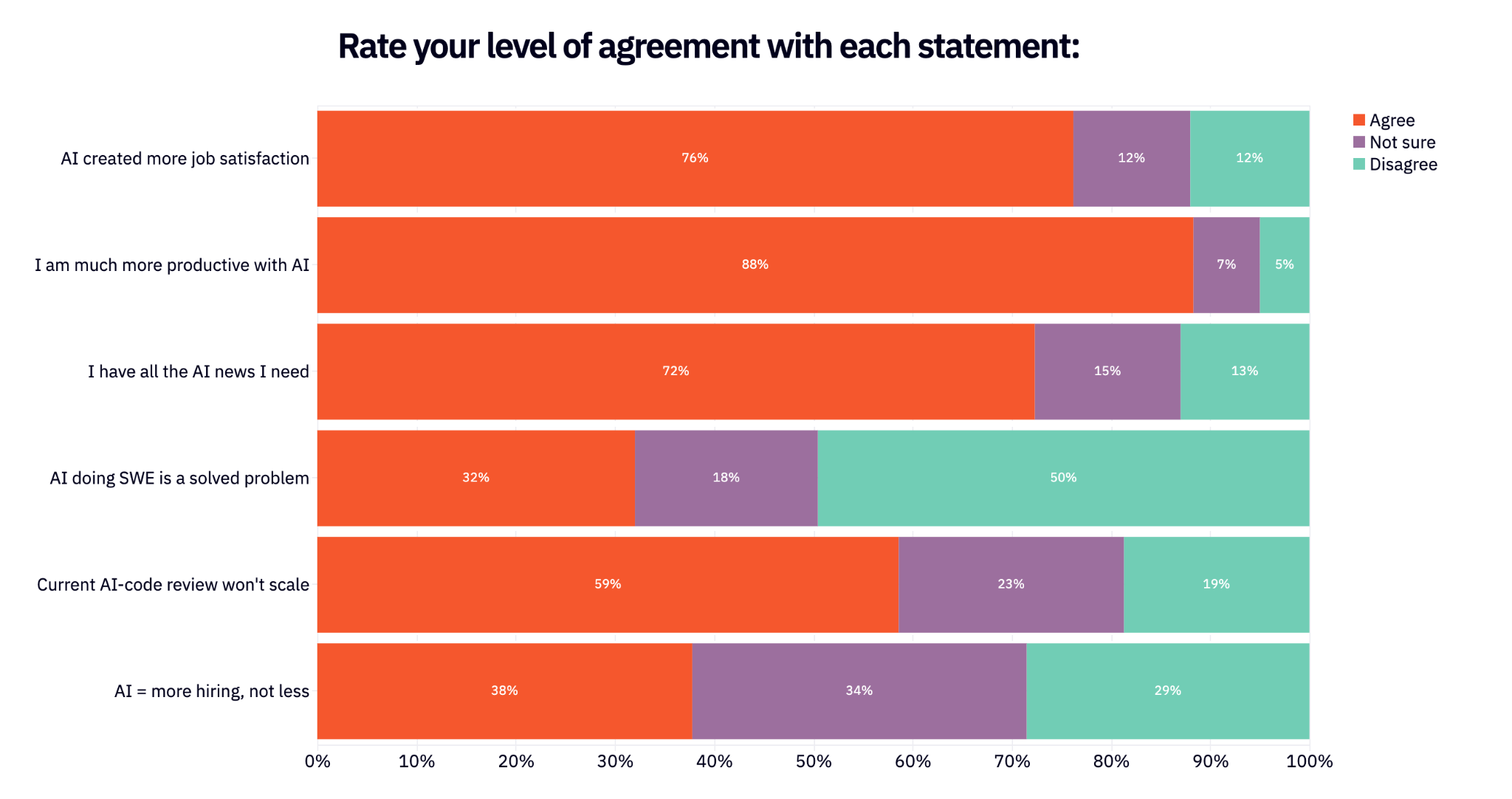
Finally, we asked everyone if they agree, aren’t sure, or disagree on some fundamental takes related to AI Engineering.
We then did the same thing, but for 5 years out. Will agents be making purchasing decisions? Will SOTA models still be closed source?
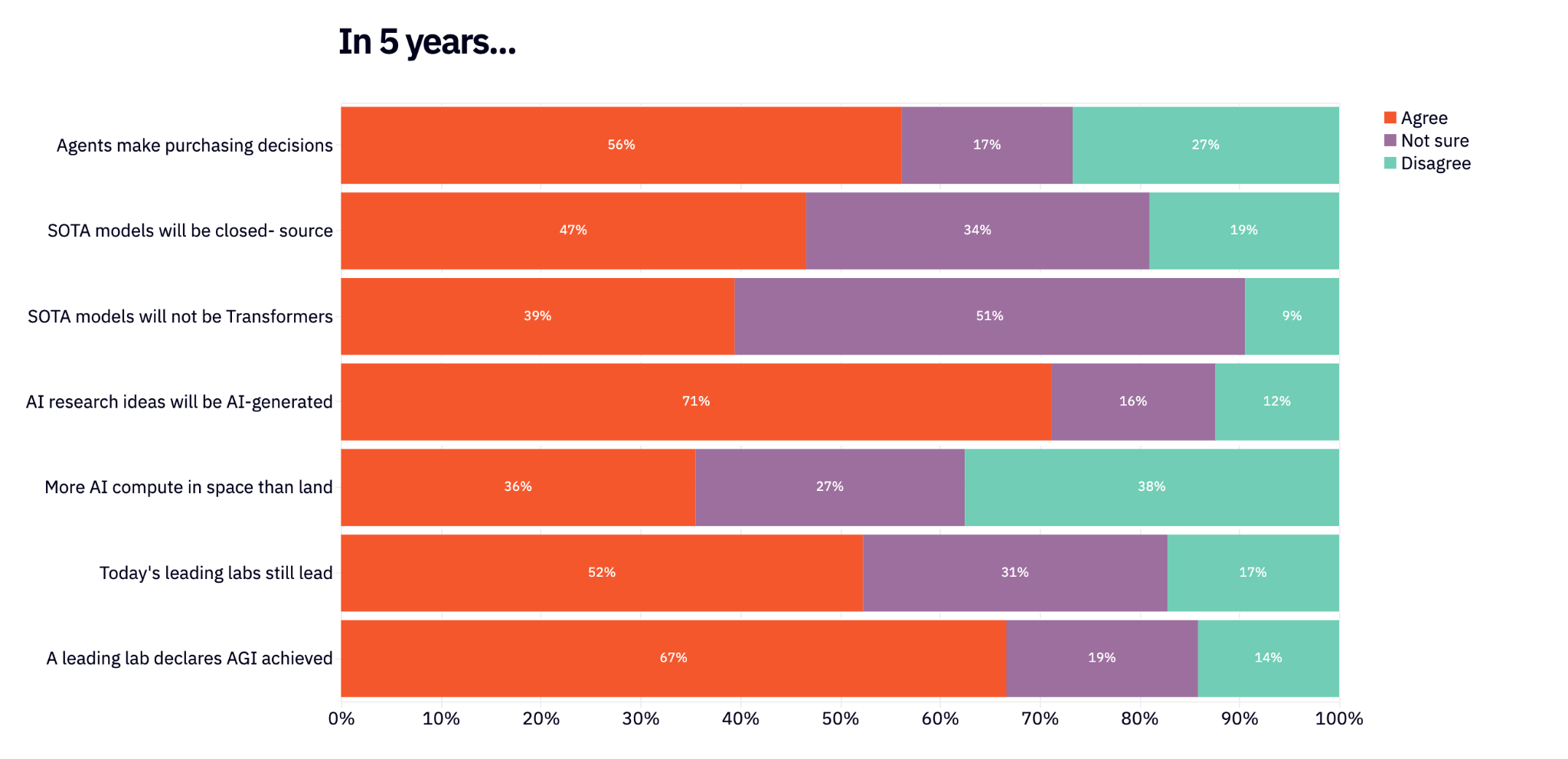
Save for maybe AI-generated AI research ideas, the only commonality among these topics is that everyone is split on them. Interestingly, only 9% of respondents believe that Transformers are the final boss architecture (and yet 5 years into this, we still don’t have a viable alternative).
–
Anywhere you’d want more data? Questions we should ask next year? Let us know via email or X.





