Close your eyes and picture the platonic ideal compute infra. The machine of your dreams, built to run exactly how you want it. What does it look like?
How do you create one? How long does it take? How do you size and allocate resources?
What’s the API for accessing and using it? How does it handle authentication? How does it deal with persisting data?
How much does it cost? What is the pricing model? Is it predictable or does it flex completely based on your usage?
These are not new questions. In fact, they’ve been the subject of much inquiry and product building for probably decades now. The modern developer has no shortage of ways to access computers over the internet: all the way from bare metal, to good old EC2, to container-based services, all the way up towards managed PaaS like Vercel, and then even to just functions that don’t make you choose a computer at all. All in all, there are thousands of ways to run your code somewhere on the web.
This background makes it all the more curious that exe.dev, which is launching today, is building a new way to run your code somewhere on the web.
Infrastructure for the new age
There's a pattern in computing that repeats with remarkable consistency: a new application paradigm emerges, and for a brief, awkward period, we try to run it on yesterday’s infrastructure. Mainframe architectures creaked under the weight of client-server applications. Client-server infrastructure buckled when the web arrived; recall the early days of Facebook where engineers were sprinting to rack Dell servers to keep up with growth. And the first wave of cloud-native apps were shoehorned into virtual machines designed for monoliths before containers and orchestrators caught up.
We're clearly in one of those moments again. The rise of coding agents and LLM-driven development has created a fundamentally new way of building software — one where you can describe an application in three sentences on your phone, in the middle of a conversation, and have it running minutes later. The velocity of software creation has undergone a step change.
And yet…the infrastructure we're deploying to was designed for the old world. It has completely outdated assumptions around sequential development, manual deployment pipelines, and critically, applications that justify the overhead of provisioning, configuring, and securing a production environment.
David Crawshaw — formerly co-founder of Tailscale, where he helped build one of the most elegant and beloved networking products of the last decade — saw this mismatch early. He and his cofounder (Josh Bleecher-Snyder) + team at exe.dev spent two years arriving at a thesis that sounds simple but has deep implications: the correct modern application infrastructure is just…a computer.
This all started via a somewhat circuitous route. exe.dev's team began by building an AI coding agent (about two weeks before Claude Code shipped, as it happens). Through that process, they realized they'd spent most of their engineering time not on the agent itself but on the surrounding machinery — getting containers to work in the cloud, connecting them to GitHub, wiring up the plumbing that every agent-driven workflow needs. Ironically, surprisingly, building the agent turned out to be the straightforward part — they'd spent most of their engineering time on the infrastructure surrounding it.
This is usually where I’ll write “so they set out to build the infrastructure they wish they had had.” Well, sort of. The problem is that there really is no single correct agent workflow. The SDLC as we've known it — write code, run locally, deploy to production — is being disassembled and rebuilt in real time. It looks different for solo developers than for small teams, and different again for large organizations. What you actually need are good primitives for building your own workflows.
So what are these primitives, exactly?
What does infrastructure look like when you design it for this new reality? What is the VM of your dreams…or your agent’s dreams?
David and team landed on a set of core convictions that shaped exe.dev's architecture.
- The marginal cost of a VM should be zero
This is perhaps the most consequential design decision in the product. On exe.dev you buy a fixed allocation of compute — say, 2 CPUs and 8GB of RAM — and then spin up as many VMs as you want within that envelope. It can be one VM or twenty-five. The compute is shared, the VMs are free at the margin.
This is important because the economics of software creation have totally changed. Projects aren’t big, planned things anymore. In fact, you might spin up three projects on the walk to the coffee shop.
Most of them will be worth precisely nothing. You don't want to commit to five dollars a month for something you think is worth thirty cents (or, again, nothing). The old model — pay per VM, per instance, per container — creates friction at exactly the wrong moment: the moment of creation. Exe.dev removes that friction entirely. The psychological cost of trying something drops to zero, which is where it should be when an idea is three sentences long.
- Everything is private by default, shared like a Google Doc
In the traditional cloud, your application is on the public internet the moment you deploy it. You then spend hours with IP tables and security groups and application-layer auth trying to lock it back down. exe.dev inverts this: every exe.dev VM starts private. Only you can reach it. Sharing happens through Google Docs-style links — you send someone a URL, they authenticate, they're in. You can share with specific email addresses at specific permission levels.
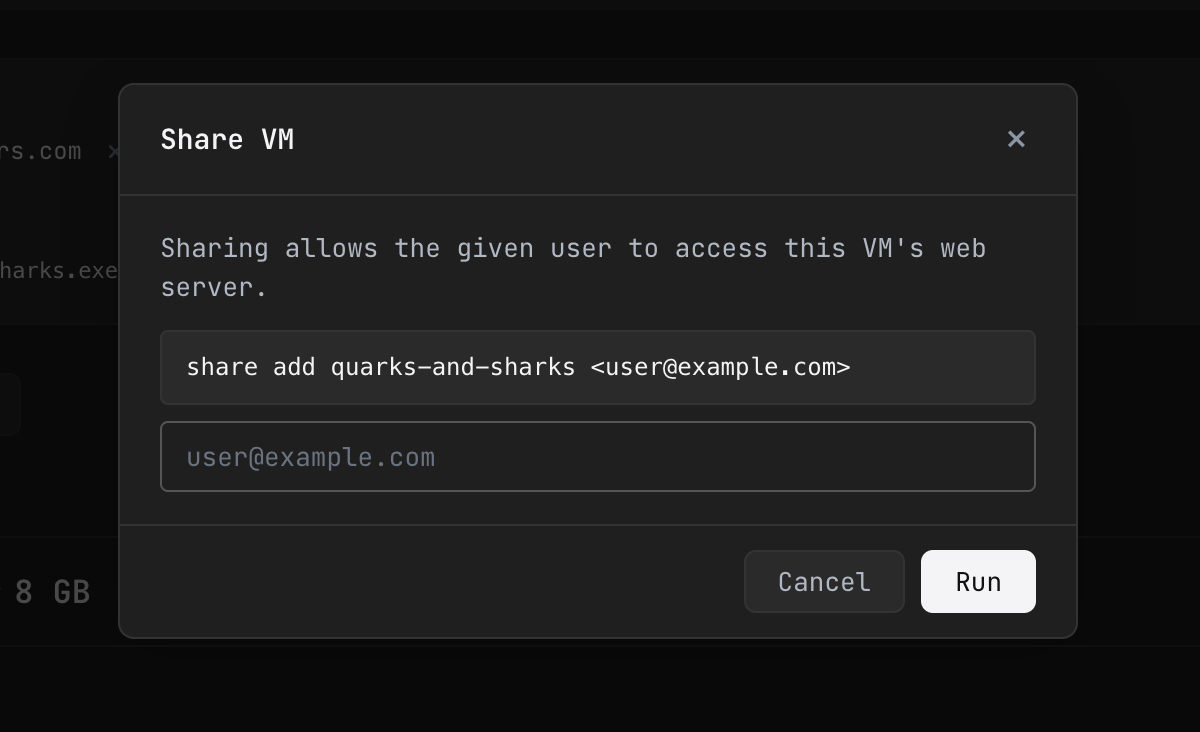
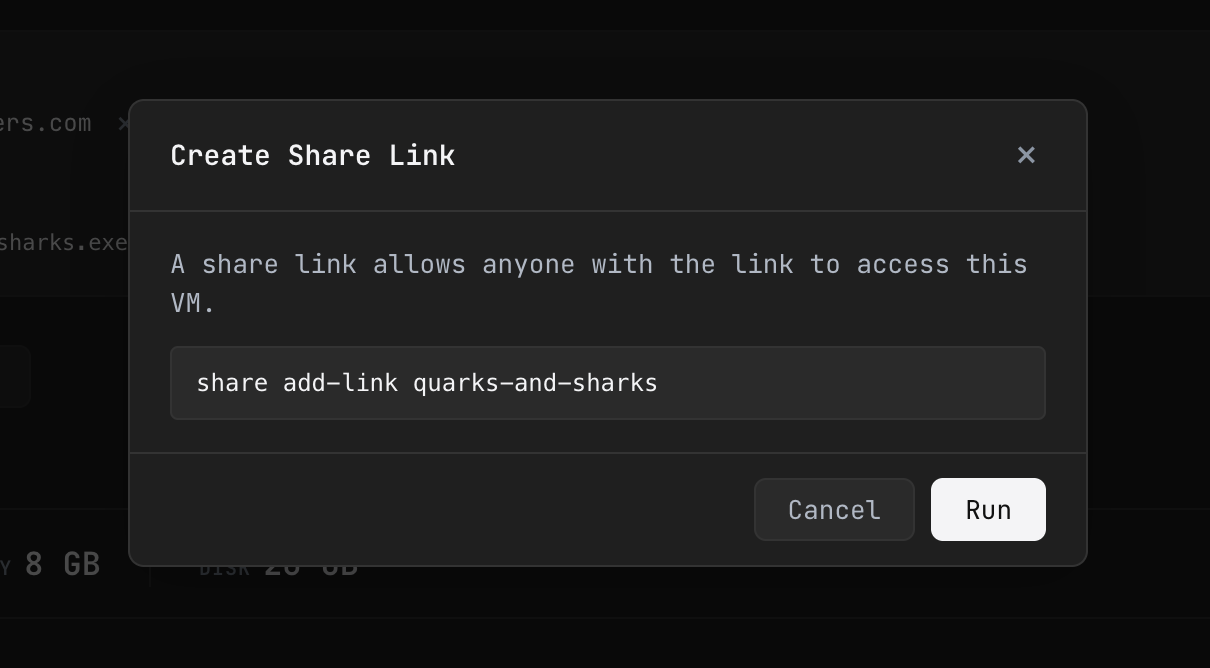
Under the hood, this is an IAM proxy — the same pattern every major cloud ships, except theirs typically require "a simple matter of writing some JSON" followed by what feels like an incantation ritual. In exe.dev though TLS, DNS, reverse proxying, and authentication are all handled automatically as smart defaults. You never have to think about it. This is critical for the agent era, where you're constantly spinning up small services that need to be reachable by your team but shouldn't be reachable by the world.
- LLM tokens are a compute primitive
A computer used to be defined by four things: CPU, memory, storage, network. LLM tokens are now a fifth primitive. Every heuristic, every small decision engine, every piece of glue logic in your application will eventually call a model. And so exe.dev ships with an LLM gateway attached to every account — tokens on tap, available to every VM, without managing API keys or provider integrations.
This connects to a broader philosophy about integrations. When you attach GitHub to your exe.dev account, your VMs can clone repositories through a secure integration layer. The actual GitHub tokens live in exe.dev's infrastructure, never on your VM. An agent running on your machine can reach GitHub and pull code, but there's no token to exfiltrate, no credential to leak. The same pattern applies to LLM access. In an era where agents have increasing power over your systems, minimizing the blast radius of a compromised token is a first-order design concern.
- Develop in production
I probably should have started with this one.
The traditional build-deploy cycle exists because writing software used to be expensive enough to justify the overhead. When a feature takes three days to build, you need to set up a GitHub repository, a CI pipeline, a staging environment — the whole development apparatus. But when that same feature is three sentences of natural language and an agent executes it in minutes, the build-deploy machinery becomes a larger fraction of the total lifecycle than the actual development. It doesn’t make sense anymore.
Exe.dev collapses the development and production environments into one. You edit in place. The running process is the thing you're developing.
This has a second-order benefit because agents become dramatically more effective when they can see the whole picture. Drop a capable model onto a machine with the source code, the running process, the logs, and a browser, and it can diagnose and fix problems end-to-end. It sees a deployment fail, takes a screenshot with Chrome, checks the logs, curls the endpoint, identifies the issue, fixes the code, restarts the process.
The exe team does this today, routinely, for internal tooling. The set of programs you can build this way is still small — you're building Ramp's internal tools, not Ramp itself — but six months ago, the set was zero.
Some of the engineering under the exe.dev hood
To deliver these primitives, the exe.dev team has cooked on several interesting problems in systems design.
Copy-on-write VM cloning
One crazy thing that you can do in exe.dev is duplicate a full VM — operating system, installed packages, running state, all of it — in literally seconds. The command is cp myvm myvm-copy, and you've got a complete second environment. This is actually how David does feature branches: instead of git branches, he copies his entire development VM, works on the copy, and discards it when done.
The speed comes from a copy-on-write filesystem at the block device layer. Each VM image is a couple of gigabytes (it's full Ubuntu), but cloning doesn't replicate those bytes upfront. Blocks are shared and only diverge as writes occur. This work might be invisible to the user but required months of engineering to get right, via the filesystem, the block device management, the memory handling that lets Linux compress and swap VM state across multiple tiers depending on how aggressively you want to pack machines.
Anycast and the global load balancer
Exe.dev built its own global anycast network and load balancer, the kind of infrastructure you'd normally buy from Cloudflare or AWS. David tested it by building a monitoring tool (on exe.dev, naturally, using Shelley on his phone during a meeting) that bounces between Mullvad VPN exit nodes around the world, connects to exe.dev's anycast addresses, and compares the actual routing against what was expected. The tool runs every 15 minutes, generates MTR traces when routes are wrong, and the bug reports it produced were good enough that exe.dev's network provider used them to fix BGP addressing issues.
This is itself, funny enough, an example of the kind of application exe.dev is designed for: a little app that’s kind of useful. It was written conversationally on a phone, runs unattended in production, and would have been a multi-day project six months ago.
Shelley, the accidental coding agent
Shelley is exe.dev's web-based coding agent — a chat interface that can drive a VM, install packages, write code, take screenshots with a headless browser, and iterate on running applications. The team built it almost as an afterthought, expecting most users to SSH in or use Claude Code or Cursor. It was about half of one person's engineering time.
It turned out to be one of exe.dev’s most popular features. Users weren't wedded to any particular agent harness, which I find both unsurprising and significant. David now does most of his own development through Shelley, on his phone, including development work on exe.dev itself — with carefully scoped read-only access to production logs so the agent can understand the production environment without being able to break it.
Exe.dev is worth your bet
The best pitch I can give you for exe.dev is that it’s just the easiest possible way to get little apps up and running. In the create VM screen, you can give Shelley a prompt.
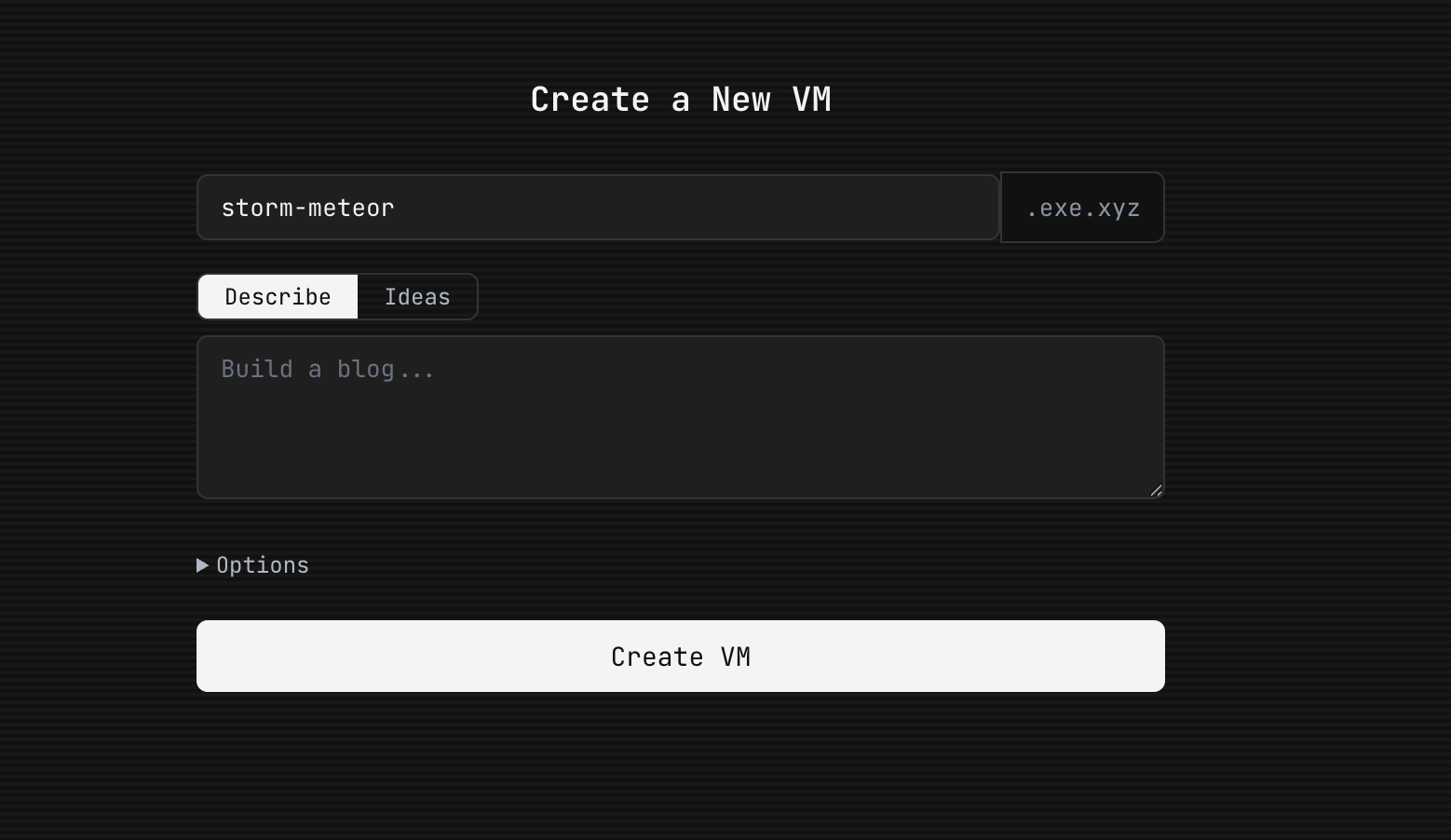
I went from silly idea to working app in literally 10 seconds, sharable and running on the web. The killer demo for exe.dev might be as simple as that.
There's an inherent wager in exe.dev's design. The platform is built for a world where models keep getting better, where the set of applications you can build conversationally expands from internal dashboards and monitoring tools to progressively more complex software. The infrastructure they've built for "little apps" is the same infrastructure you'd want for larger applications in a world where agents are capable enough to build and maintain them…one day.
The developer tools playbook has always worked this way. Developers build small things on platforms that feel good to use, and then the platforms they adopted for small things become the platforms they use for big things. Think of Digital Ocean's $5 droplet or Heroku's simple git push. The pattern has been running for decades, and we believe exe.dev is positioned to be this era's version of it.
So we’re thrilled to be partnering with David and the exe.dev team on this journey and lead their $25M Series A, alongside CRV and Heavybit. Welcome to the Amplify family!



