
Why TigerBeetle is the most interesting database in the world
Disclosure: TigerBeetle is an Amplify portfolio company.
By many measures it’s safe to say that TigerBeetle is the most interesting database in the world. Like Costanza in Seinfeld, they seem to do the opposite of everyone else:
- Most teams write code fast. TigerBeetle tries to write code slow.
- Most teams treat testing as a necessary evil. TigerBeetle is built entirely on Deterministic Simulation Testing (DST).
- Most teams build their software on top of loads of other software. TigerBeetle has zero dependencies.
There’s even more. TigerBeetle enforces static memory allocation. They keep assertions enabled in production. They chose Viewstamped Replication over Raft, and even Zig instead of Rust!
This read is going to go behind the scenes of how TigerBeetle came to be, the incredibly novel software they’ve built, and all of the wacky, wonderful things that make them so special. Based on extensive interviews with the TigerBeetle team, we’re going to cover a few topics in technical detail:
- Why transactional databases should think in debits and credits, not SQL
- An (actually) modern database: distributed by default, handling storage faults, and why TigerBeetle uses Zig
- VOPR, TigerBeetle’s Deterministic Simulation Testing cluster
- TigerStyle, and why you should use assertions
Let's get to it.
Why we need a database that thinks in debits and credits
TigerBeetle’s website calls it “The Financial Transactions Database.” Its primitives are debits and credits, which are things you may be familiar with from your accounting requirement in college. And if you’re not a bank, you’re probably thinking this whole thing isn’t really for you. But Joran (TigerBeetle’s creator) would tell you otherwise: financial transactions, i.e. debits and credits, are actually exactly what transactional SQL was originally designed for.
Way back in 1985, Jim Gray (who would later win a Turing Award) wrote a seminal paper on transactions, titled A Measure of Transaction Processing Power. If you’ve heard of it before, it’s because in it, Gray defined a metric that 40 years later is still the most important measure for a database: TPS, or transactions per second. This would end up leading to such a fervent benchmark war among databases that an objective council – the TPC – needed to be formed to moderate.

But what does the “T” in TPS actually mean? What is a transaction?
Your first guess might be a SQL transaction, but that’s not it. Gray actually defined it as a business transaction derived from the real world. Which is the reason databases were invented in the first place: to power businesses. And indeed, 20 years later, Gray continued to see the standard measure of transaction processing as a “DebitCredit:”
“A database system to debit a bank account, do the standard double-entry bookkeeping and then reply to the terminal.”
Mind you, SQL had already been around since the 70s at this point. And yet the luminary Gray still chose the debit/credit model – because it was the canonical example of an everyday transaction. Debit/credit is the lingua franca of what it means to transact. It is not just for accounting and banks. It’s the reason for a database to provide guarantees like ACID in the first place.
And yet, if you want to use a SQL database to implement debits and credits today, you are probably going to have a bad time. To handle one debit/credit, a typical system – like the central bank switch that Joran consulted on in 2020 – needs to query account balances, lock those rows, wait for decisions in code, then write back and record the debit/credit. All in all, you’re looking at 10-20 SQL queries back and forth, while holding row locks across the network roundtrip time, for each transaction. This gets even worse when you consider the problem of hot rows, where many transactions often need to touch the same set of “house accounts”.
All the while (for better or worse), the world is moving faster and faster towards an “everything is a transaction” model. Countries like India and Brazil are doing billions of transactions per month in instant payments. With FedNow in the U.S., we’re not far away from that reality either. Meanwhile, other sectors like energy, gaming, and cloud are all moving towards real-time billing. In less than a decade, the world has become at least three orders of magnitude more transactional. And yet the SQL databases we still use to power this are 20-30 years old. Can they hold up?
This is where TigerBeetle comes in. They designed a state-of-the-art database, from the ground up, to power the next era of transactions. In TigerBeetle, a debit/credit is a first class primitive and 8,190 of them can pack into a single 1MiB query via a one solitary roundtrip to the database. They call it “The 1000x Performance Idea,” but in Joran’s words it’s “nothing special”.
They say databases take a decade to build. But TigerBeetle is complete and pretty much Jepsen-proof after just 3 and a half years. In June 2025, Kyle Kingsbury showed he was unable to break TigerBeetle’s foundations (he found 1 correctness bug in the read query engine, not affecting durability), even while corrupting the whole thing on every machine in various places.
The obvious question here – how? How did TigerBeetle ship a production-ready, Jepsen-passing consensus and storage engine in 3.5 years when it typically takes a decade or more?
An (actually) modern database: distributed by default, why TigerBeetle uses Zig, and handling storage faults
Imagine you wake up today and wisely decide to build a database from scratch. Instead of investing in the technology of 30 years ago – when the most popular relational databases today were built – you can pick any advancements in architecture, hardware, language, or research since then to implement. How would you build it? What would you utilize?
Distributed by default
One thing you’d probably start with is the deployment model.
When Postgres and MySQL were built, in a world of big iron (on-prem hardware), the dominant paradigm was single node. Now, in a world of shared cloud hardware, it’s distributed. It’s not safe enough to store your transactions only on a single disk or server. A modern database needs to replicate your transactions, with strict serializability, across machines, for redundancy, fault tolerance and high availability. And yet some of the most popular OLTP databases in the world today are still highly dependent on a single node architecture. Automated failover, at least with zero data loss in the cut over, is not always baked in by default.
So TigerBeetle built their database to be distributed by default. Doing that comes with some of the obvious things you need to do, like consensus. But the developer experience for running TigerBeetle distributed is very simple: you just install the binary on however many machines you want in the cluster. No async replication, no Zookeeper, etc. To make this possible, TigerBeetle invested heavily in their consensus protocol implementation, adopting the pioneering Viewstamped Replication from MIT. This is part of why TigerBeetle has zero dependencies, apart from the Zig toolchain — they literally invested in all their core dependencies.
Clock fault tolerance
Distributed by default also shows up in some unlikely places. For example: have you ever thought of a clock fault model?
Though it’s not technically required or advised for consensus – which uses logical clocks and not physical clocks – remember that TigerBeetle is a transactions database. The physical timestamps of transactions need to be accurate and comparable across different financial systems for auditing and compliance.
And here, readers will note that Linux has several clocks: CLOCK_MONOTONIC_RAW, CLOCK_MONOTONIC and CLOCK_BOOTTIME. All have slight but important differences. Which is the best monotonic clock to use? (clue: It doesn’t say MONOTONIC on the tin)
The challenge is that physical imperfections in hardware clocks cause clocks to tick at different speeds, so that time passes faster or slower than it should. These kinds of “drift” errors eventually add up to significant “skew” errors within a short space of time. Most of the time, Network Time Protocol (NTP) would correct for these errors. But if NTP silently stops working because of a partial network outage, then a highly available consensus cluster might otherwise be running blind, in the dark.
But even this is something TigerBeetle thought about. They combine the majority of clocks in the cluster to construct a fault-tolerant clock called “cluster time”. This cluster time then gets used to bring a server’s system time back into line if necessary, or shut down safely if TigerBeetle detects that there are too many faulty clocks (e.g. TigerBeetle can actually detect when something like Chrony, PTP, or NTP have stopped working and alert the operator).
They do this by tracking offset clock times between different TigerBeetle servers, sampling them, and passing them through Marzullo’s algorithm to estimate the most accurate possible interval (again, just to get a sense of whether clocks are being synced by the underlying clock sync protocol correctly).
Small things like this are exactly why distributed by default is hard, and doesn’t work as an add-on for older database models. You can read more about this in TigerBeetle's 3 clocks are better than one blog post.
Handling storage faults
Another piece of “distributed by default” that deserves its own header is how TigerBeetle handles storage faults (or even the fact it handles them at all). Traditional databases assume that if disks fail, they do so predictably with a nice error message. For example, even SQLite’s docs are clear that:
SQLite does not add any redundancy to the database file for the purpose of detecting corruption or I/O errors. SQLite assumes that the data it reads is exactly the same data that it previously wrote.
In reality, there are many more sinister possibilities: disks can silently return corrupt data, misdirect I/O (on the read or write path), or just suddenly get really slow (called gray failure in the research), all without returning error codes.
TigerBeetle is built to be storage fault tolerant:
- TigerBeetle uses Protocol Aware Recovery to remain available unless all copies of a piece of data get corrupted on every single replica.
- All data in TigerBeetle is immutable, checksummed, and hash-chained, providing a strong guarantee that no corruption or tampering happened.
- TigerBeetle puts as little software as possible between itself and the disk, including a custom page cache, writing data to disk with O_DIRECT, and even running on a raw block device directly (no filesystem necessary — to sidestep filesystem bugs which do tend to happen from time to time).
- They built their own implementation of LSM instead of using an off-the-shelf one – they call it an LSM Forest, which is something like 20 different LSM trees.
As far as I’m aware TigerBeetle is the only distributed database that not only claims to be storage fault tolerant, but was also tested pretty hard and validated by Jepsen to be. If you have a local machine failure where even just a disk sector fails, then that storage engine is connected to the global consensus, and it can use the cluster to self heal. This is also a great example of why the modern database having access to modern research matters: Protocol-Aware Recovery, which enables TigerBeetle to survive disk failures like this, is fairly recent (2018) research.

TigerBeetle in Zig
Another thing you’d think about when building a modern database from scratch is your choice of programming language. Postgres is written in C (c. 1970s), MySQL in C and C++ (1979), and MSSQL as well in C and C++. But programming languages have come a long way in the past 40 years. If you had your choice, what would you build a database in today?
The answer would probably be Rust or Zig. And indeed, TigerBeetle is built 100% in Zig:
- You get the whole C ecosystem available to you, extended with a phenomenal toolchain and compiler.
- It’s easy to write, and especially easy to read, in some cases as easy as TypeScript (just a lot faster).
- Zig lets you statically allocate memory, which is a core principle of TigerBeetle.
- Zig has a great developer experience and you can learn it quickly (which ergo means you can get into the TigerBeetle src quickly).
Of course, as new systems languages, Zig and Rust are related, and some of the early Rust team now work at TigerBeetle, including Matklad (creator of Rust Analyzer) and Brian Anderson (co-creator of Rust with Graydon). They’ve written extensively about these languages and why Joran chose Zig in particular for TigerBeetle, given their design goals.
And here, of course, TigerBeetle is fanatical about static memory allocation, which I’ll talk more about in the next section. Not using dynamic memory allocation is “hard mode” in Rust (as matklad wrote about here), but a breeze in Zig.
Deterministic Simulation Testing and the VOPR
Sometimes, Deterministic Simulation Testing (DST) feels like the most transformational technology that the fewest developers know about. It’s a novel testing technique made popular by the FoundationDB team (which now belongs to Apple); they used it to develop a more secure, bug-free distributed database in a shorter time span than arguably anyone had done before.
The fundamentals of DST go something like this. In distributed systems, there are essentially infinite combinations of concurrency issues: anything from lost messages to unpredictable thread execution order. You simply cannot use old-school unit and integration tests, or your system will suck. Formal verification, a more academic discipline that works on formulaic proofs that a program runs as intended, is too expensive and slow. So what are you to do?
The answer is a simulator that deterministically runs almost every possible scenario your system will face on a specific chronological timeline. The simulator accounts for external factors too, like issues with the OS, network, or disk, or simply different latencies. All in all, DST can give you the equivalent of years’ worth of testing in a very short time period (because time itself becomes deterministic—a while true loop); and DST is particularly well suited towards databases (I/O intensive, not compute intensive). If you’re familiar with Jepsen testing, think of it as a subset of what DST can do.
TigerBeetle is one of the most pioneering startups on the planet when it comes to DST. They’ve developed their own testing cluster – it’s nicknamed VOPR, short for Viewstamped Operation Replicator (after the WOPR simulator in the movie WarGames). The VOPR constantly (and tirelessly) tests TigerBeetle under countless different conditions, covering everything from how nodes elect a leader to individual states and network faults. But it can simulate a whole distributed cluster virtually, all on a single thread.
As far as your author is aware, TigerBeetle’s VOPR is the single largest DST cluster on the planet. It runs on 1,000 CPU cores, a number so unusually large that Hetzner sent them a special email asking if they were sure they wanted that many cores. The so-called VOPR-1000 is running 24x7x365, to catch rare conditions as far as possible before production. With time abstracted deterministically, and accelerated in the simulator by a factor of (roughly) 700x, this adds up to nearly 2 millennia of simulated runtime per day.
But what if DST was fun?
Yea, distributed systems are cool. But you know what’s even cooler? Video games.
TigerBeetle turned DST into a game that lets you play through different failure scenarios in how the system reacts. You can play it here.
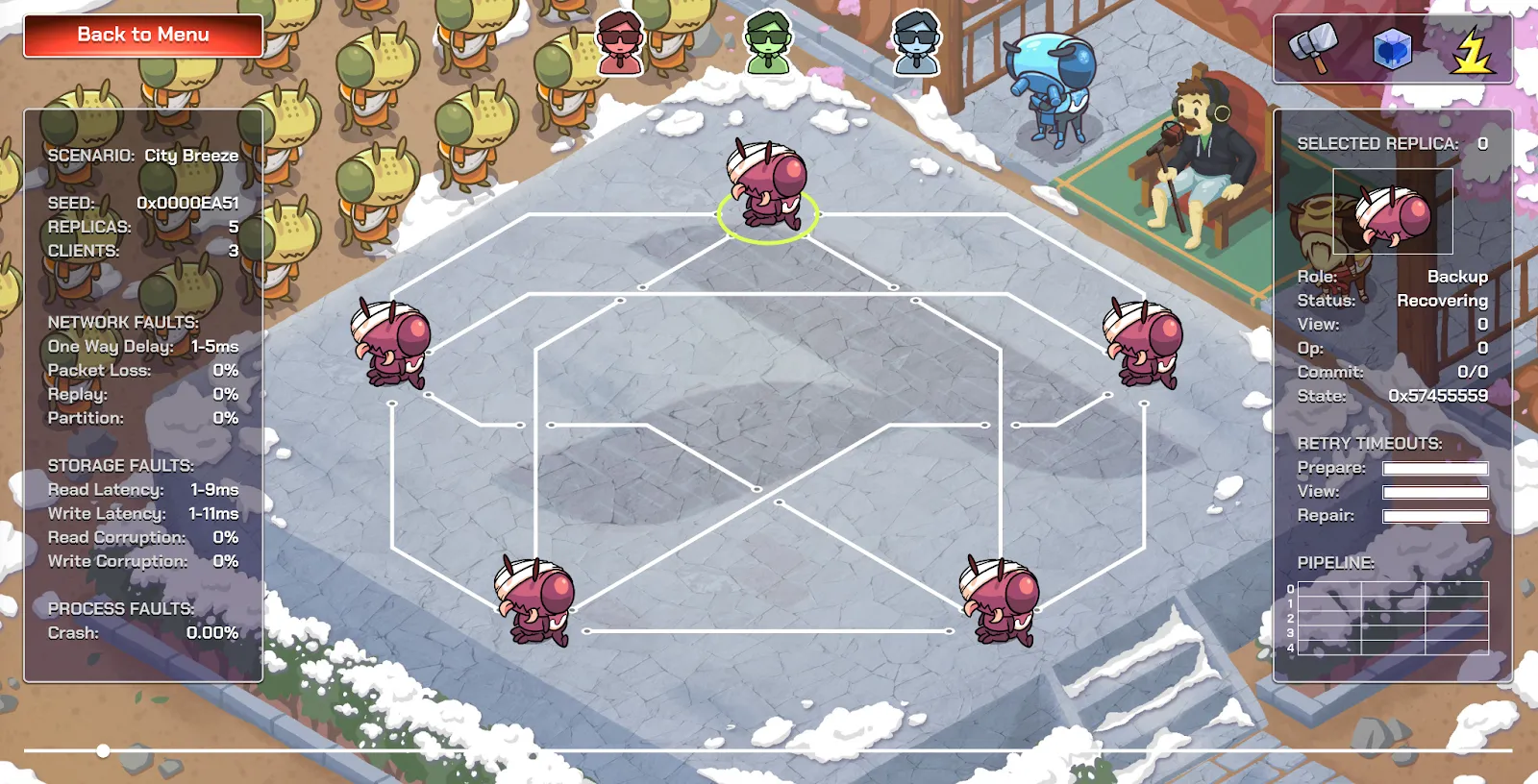
What’s perhaps even cooler is that this game is running an actual instance of the VOPR, simulating TigerBeetle…in your browser. It’s compiled to WebAssembly, and then TigerBeetle’s own engineers built a gaming frontend on top to visualize the real system
You can read more about how and why TigerBeetle built the simulator in this blog post.
TigerStyle and The Power of Ten
As you will continue to see with TigerBeetle, it is often not just the what they’ve built that catches the eye but also the how. There’s no better example than TigerStyle.
TigerStyle is TigerBeetle’s engineering methodology, public on GitHub for all to see. Here’s how they describe it:
“TigerBeetle's coding style is evolving. A collective give-and-take at the intersection of engineering and art. Numbers and human intuition. Reason and experience. First principles and knowledge. Precision and poetry. Just like music. A tight beat. A rare groove. Words that rhyme and rhymes that break. Biodigital jazz. This is what we've learned along the way. The best is yet to come.”
Biodigital jazz is a term from Tron: Legacy. In the context of the film, it represents the intertwining of human and digital elements, the chaotic yet structured nature of the “Grid” (the digital world), and the improvisational spirit of human potential within the confines of technology (I copied this from AI). For TigerBeetle, it’s an ethos of code; remembering to infuse everything they do with not just science, but art too.
More practically, TigerStyle lays out engineering and code principles for TigerBeetle, many derived from the original Power of Ten, NASA’s tenets for writing foolproof code. TigerStyle spans from the thematic, like simplicity and elegance, to the applied, like how to name things. It’s even starting to impact other companies like Resonate and Turso; and TigerStyle has even been discussed on Lex Fridman. Here are a few highlights.
Using assertions, and the Power of Ten
Speaking of the Power of Ten…one of them (Rule 5) is about assertions. The idea is simple: explicitly encode your expectations of code behavior while you are writing it, not after the fact. You write them simply in a single line as booleans: assert(a > b). TigerStyle calls for:
- Asserting all function arguments, return values, preconditions, and invariants. On average there should be at least 2 assertions per function.
- Using assertions instead of comments when the assertion is both important and surprising.
- Asserting the relationships between compile-time constants, so you can check a program’s design integrity before it even runs.
- Not just assert what should happen, but also the negative space that you don’t expect – where interesting bugs can show up.
The Power of Ten is an amazing artifact that covers so much more than just assertions…it’s a great resource for any modern programmer (and maybe we should train some LLMs on it too).
Thinking about performance
Much of TigerStyle centers around the idea that writing code is not the most important part of the cycle; instead, it’s reasoning about and designing the code. When it comes to performance, TigerStyle implores you to think about it from the start:
“The best time to solve performance, to get the huge 1000x wins, is in the design phase, which is precisely when we can't measure or profile.”
You should be doing basic napkin math on what TigerStyle calls “the four primary colors” – network, storage, memory, CPU – and how they’ll perform with respect to (“the two textures” — art!) bandwidth and latency. Then, there are a few more tactical tips, like distinguishing between the control plane and data plane, batching accesses, and extracting hot loops into stand-alone functions to reduce dependence on the compiler.
For more about TigerStyle, watch Joran’s talk at Systems Distributed.
Try it out for yourself
So is TigerBeetle a database? Yes. But it’s not much like any other database I’ve seen. They’ve taken modern research and applied it to an age-old form, giving their database unprecedented performance and stability guarantees. They’ve developed an art form around systems and storage engineering, and they haven’t forgotten to have fun along the way. And thanks to their clever use of DST, they were able to build this thing to Jepsen standards in only a few years.
You can get started with TigerBeetle here using a simple curl command.




